什么是 Dify + xParse RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合信息检索和生成式 AI 的技术。通过 RAG,大模型可以基于企业知识库进行回答,而不是仅依赖训练数据,从而提供更准确、更相关的答案。 Dify + xParse 结合了 Dify 强大的工作流能力和 xParse 专业的文档解析能力,让您能够:- 构建高质量知识库:使用 xParse 的智能解析引擎,准确提取文档内容,保留语义结构
- 智能分块处理:通过父子文本分块策略,保持文档章节完整性,提升检索效果
- 快速搭建 RAG 应用:通过 Dify 的 Chatflow 功能,快速构建基于知识库的智能问答系统
前置准备
在开始之前,您需要完成以下准备工作。第一步:获取 API Key
在使用 xParse Dify 插件之前,您需要获取 xParse 的 API Key。- 前往 TextIn 工作台 - 账号与开发者信息
- 获取您的
x-ti-app-id和x-ti-secret-code
提示:详细获取方式请参考 API Key 文档
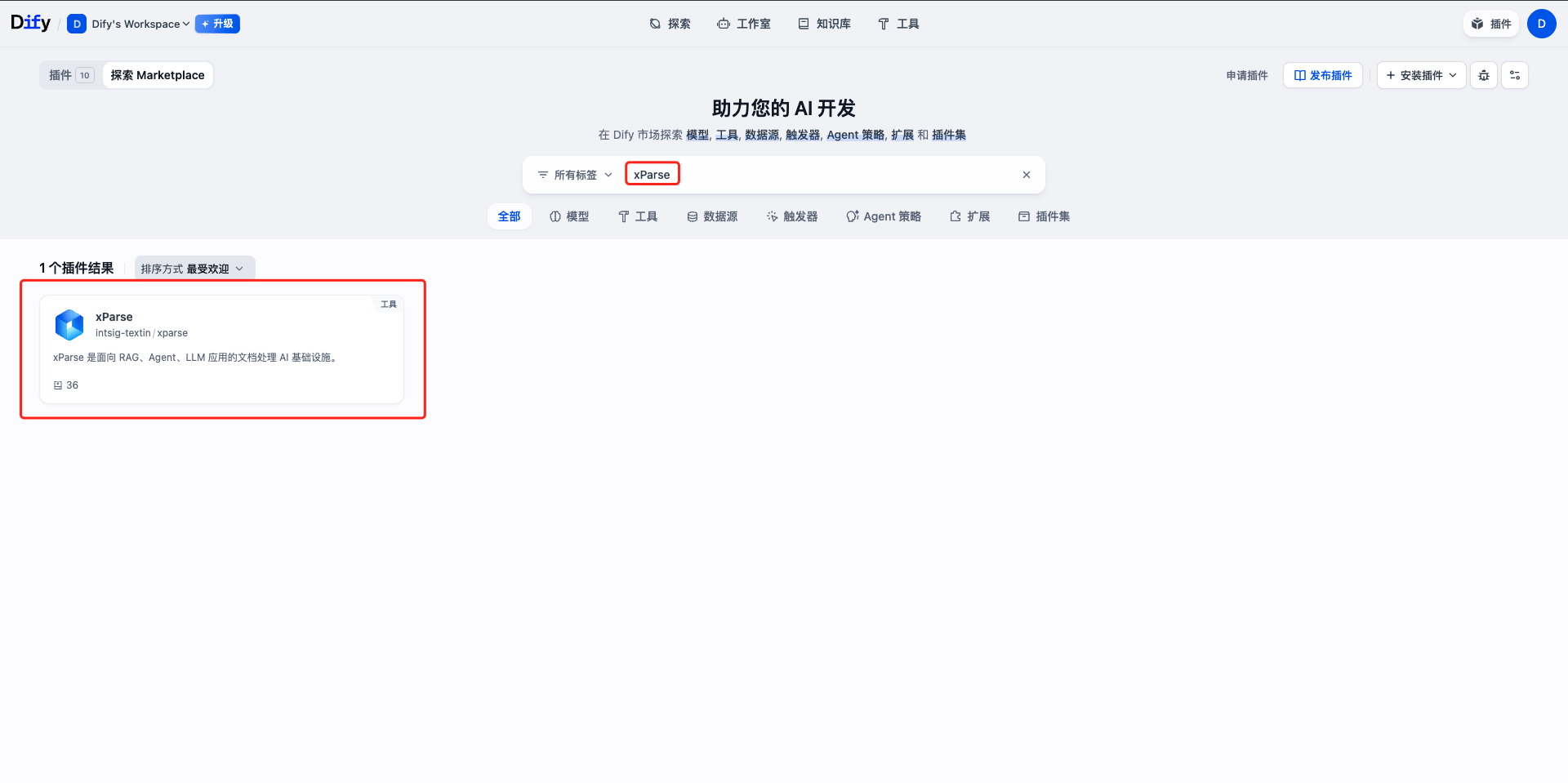
第二步:搜索和安装 xParse Dify 插件
- 登录 Dify 平台,进入插件市场
- 在搜索框中输入 “xParse”
- 找到 xParse 插件(由 intsig-textin 提供)
- 点击”安装”按钮
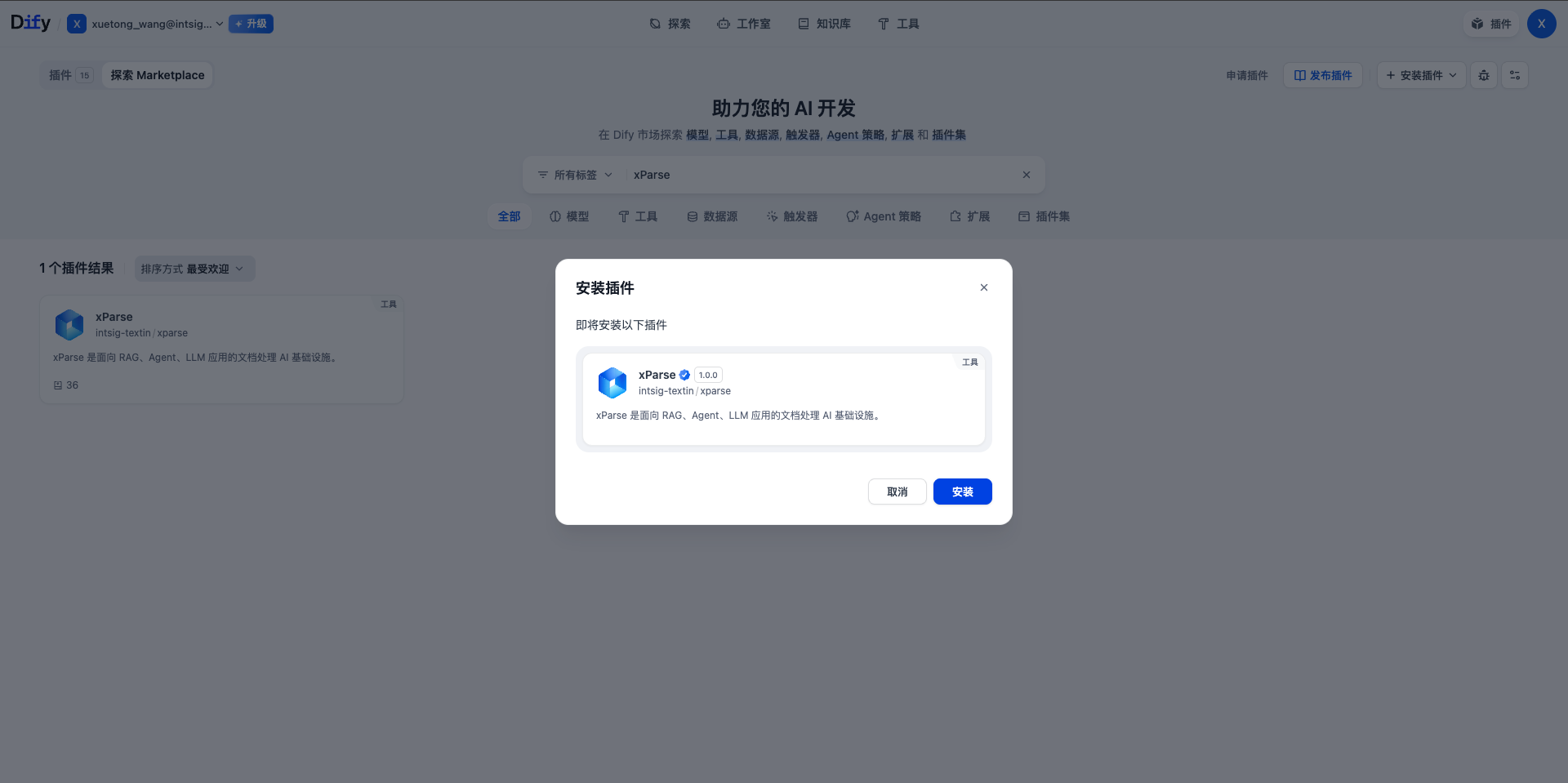
第三步:配置插件 API 信息
安装完成后,需要配置插件的 API 信息。- 进入插件管理页面
- 找到已安装的 xParse 插件
- 点击”配置”或”设置”
- 填写以下信息:
- x-ti-app-id:xParse 的应用 ID,必填
- x-ti-secret-code:xParse 的密钥,必填
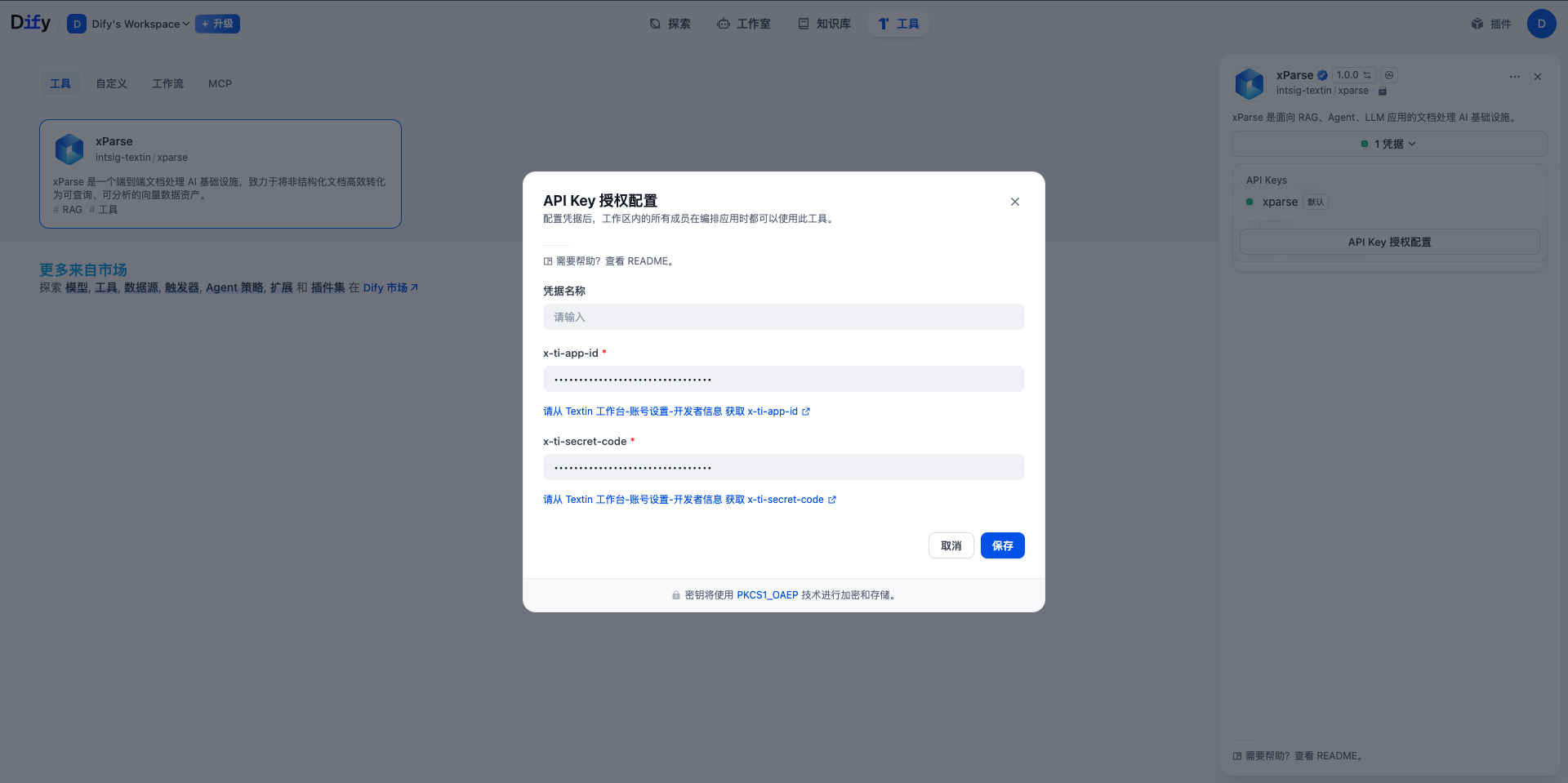
提示:请确保 API Key 信息填写正确,否则插件将无法正常工作。
创建知识库(通过知识流水线)
接下来,我们将通过 Dify 的知识流水线功能创建知识库。知识流水线提供了更灵活的配置选项,可以精确控制文档处理的每个环节。第一步:创建知识流水线
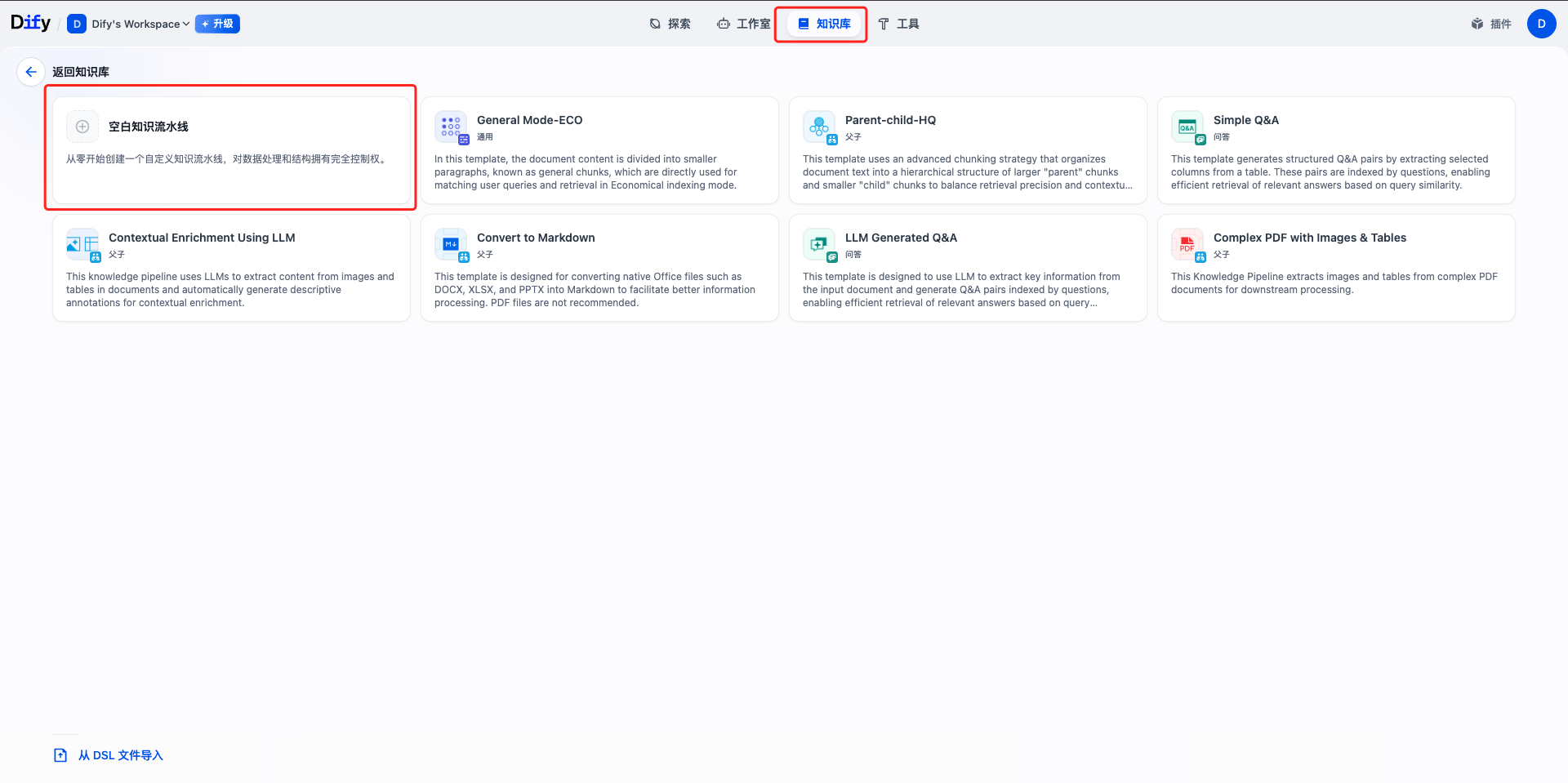
- 在 Dify 平台中,进入”知识库”页面
- 选择”通过知识流水线创建”选项
- 选择”空白知识流水线”模板
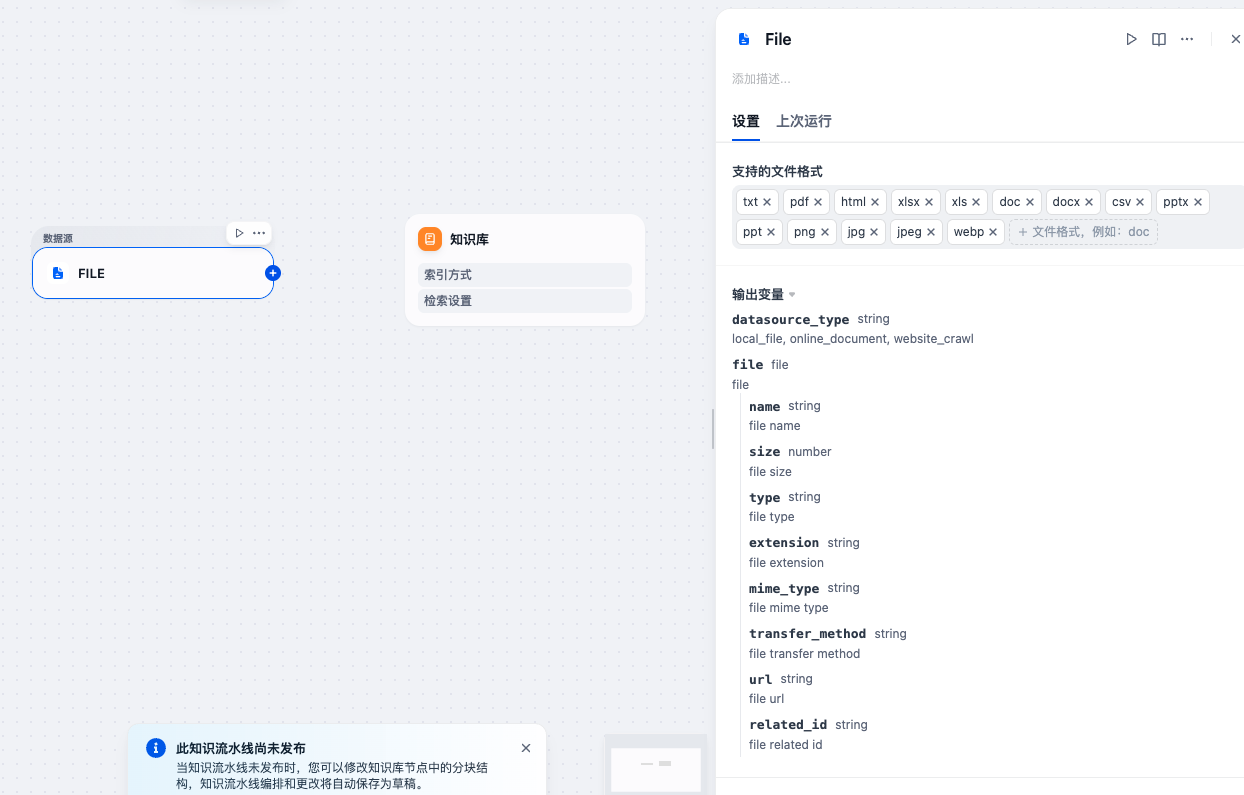
第二步:配置数据源节点
- 在知识流水线编辑器中,添加第一个节点
- 选择节点类型为”数据源”或”File”
- 配置数据源节点:
- 节点名称:可命名为”文件输入”或”数据源”
- 文件类型:支持文档和图片格式
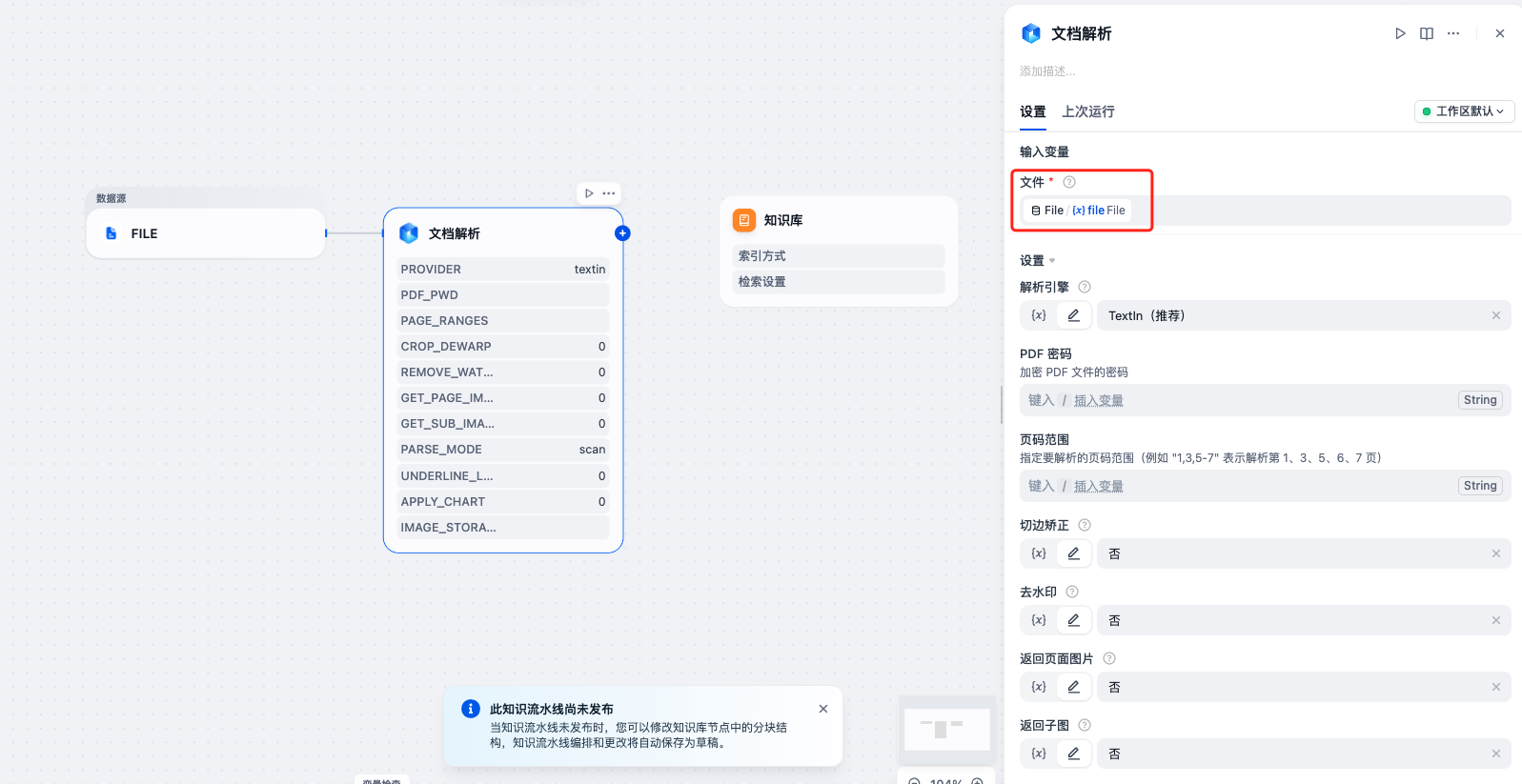
第三步:配置 xParse 文档解析节点
- 添加第二个节点,选择”工具”节点,选择 xParse -> 文档解析
- 文件输入:选择数据源节点的
file输出
- 文件输入:选择数据源节点的
- 配置解析参数:
- 解析引擎:可选择
Textin(推荐)、Textin Lite、Mineru、PaddleOCR等 - 预处理:可选择
切边矫正、去水印等(根据文档类型选择)
- 解析引擎:可选择
- 文件输入:选择要解析的文件(必填)
- 解析引擎:可选择
Textin(推荐)、Textin Lite、Mineru、PaddleOCR等(陆续接入中) - 预处理:可选择
切边矫正、去水印等
提示:其他参数详情可参考 插件说明文档
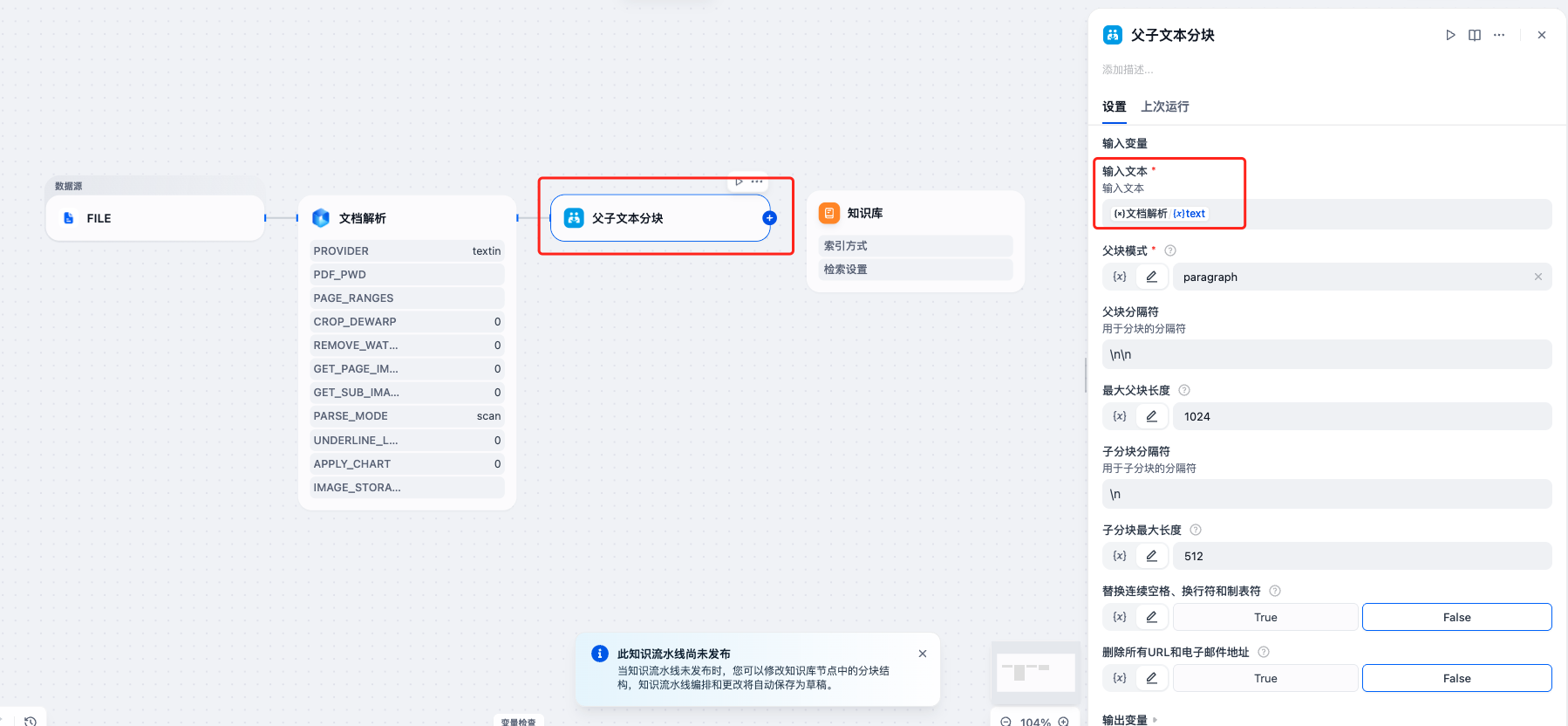
第四步:配置父子文本分块节点
- 添加第三个节点,选择 Dify 官方的”父子文本分块”节点
- 配置输入变量:
- 文本输入:选择 xParse 文档解析节点输出的
text - 其他分块参数可根据需要调整
- 文本输入:选择 xParse 文档解析节点输出的
第五步:配置知识库节点
- 添加第四个节点,选择”知识库”节点
- 配置知识库参数:
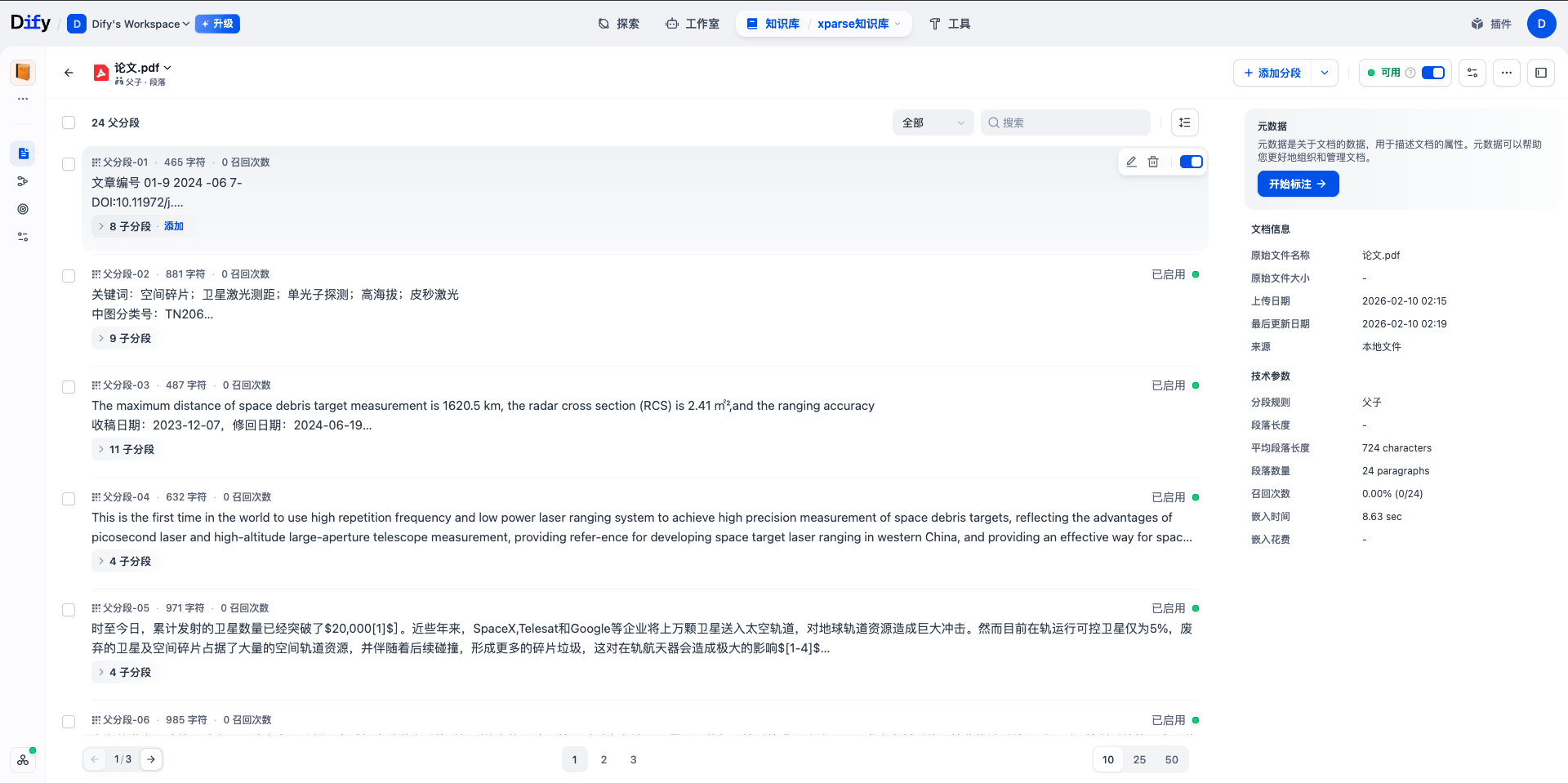
- 知识库名称:如”xparse知识库”
- 分段结构:选择”父子分块”
- 分块配置:选择上一步父子文本分块节点的
result输出 - Embedding 模型:根据需要选择,如 OpenAI 的
text-embedding-3-large - 检索设置:选择”混合检索” -> “权重设置”(根据需要调整权重参数或选择Rerank模型)
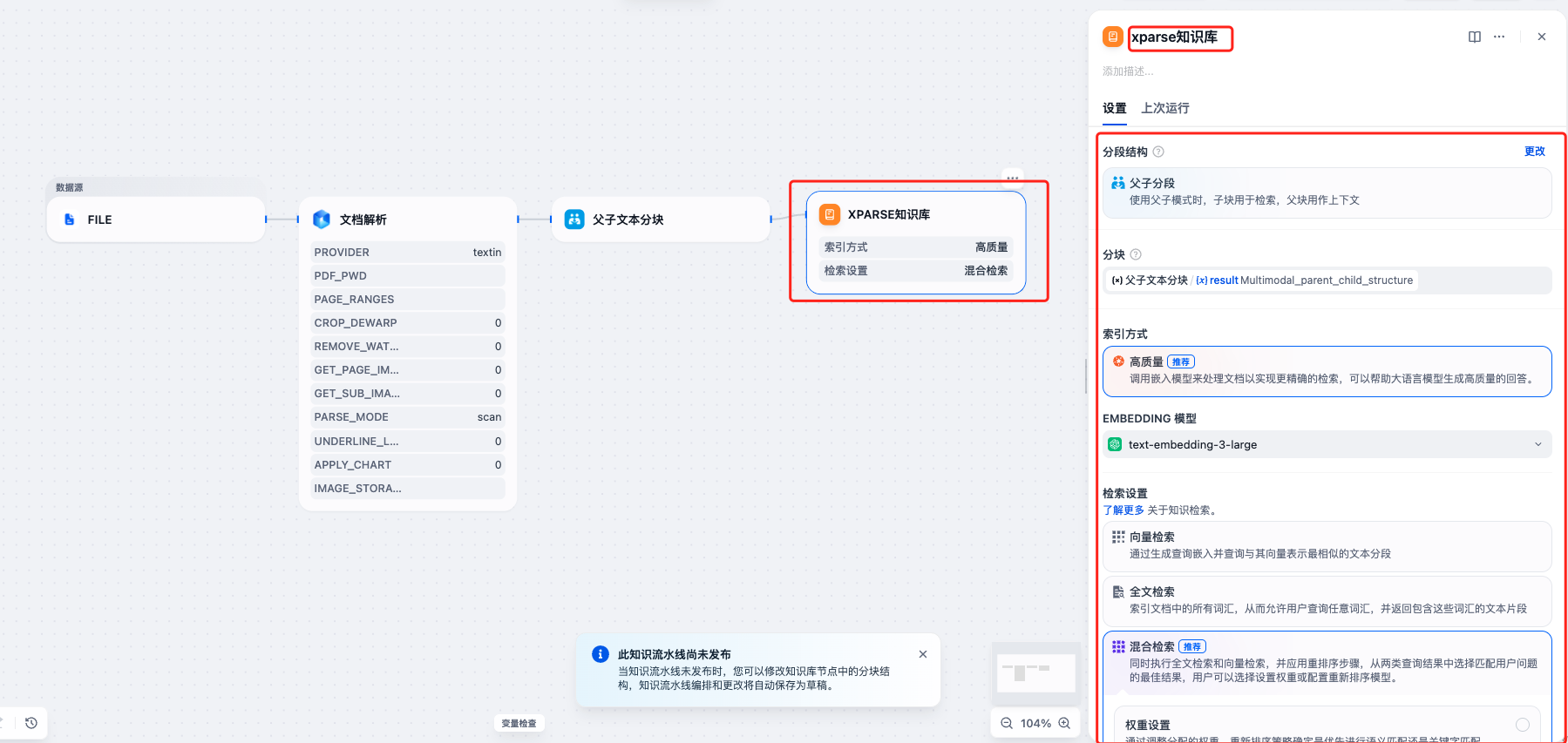
提示:混合检索结合了向量检索的语义理解能力和关键词检索的精确匹配能力,能够提供更好的检索效果。
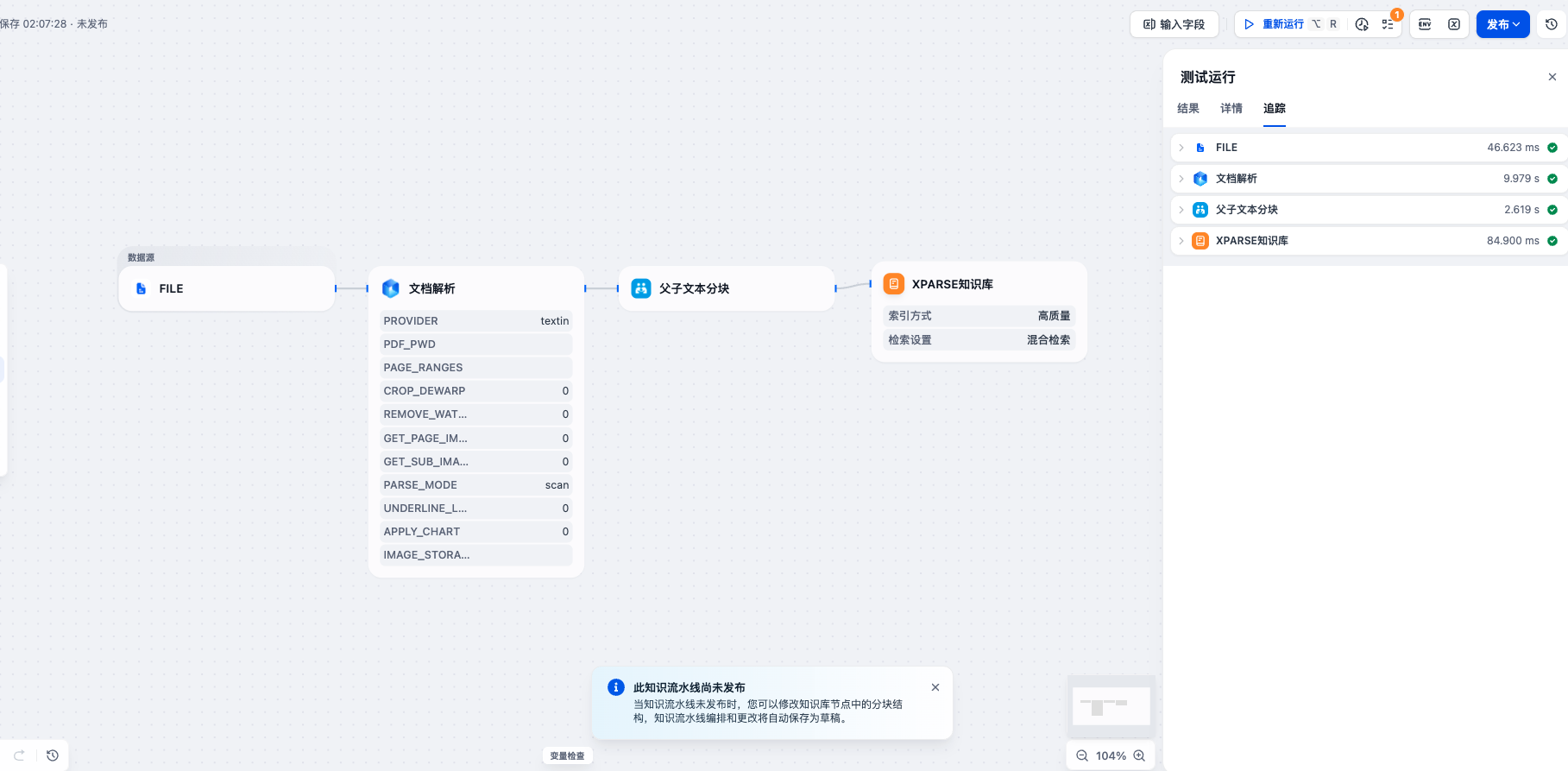
第六步:测试运行和发布
- 配置完成后,点击”测试运行”或”运行”按钮
- 检查各节点的输出是否正确:
- 数据源节点:确认文件输入正常
- xParse 解析节点:确认文档解析成功,输出
text字段 - 分块节点:确认文本分块正常,输出
result字段 - 知识库节点:确认知识库创建成功
- 如果测试通过,点击”发布”或”发布更新”按钮
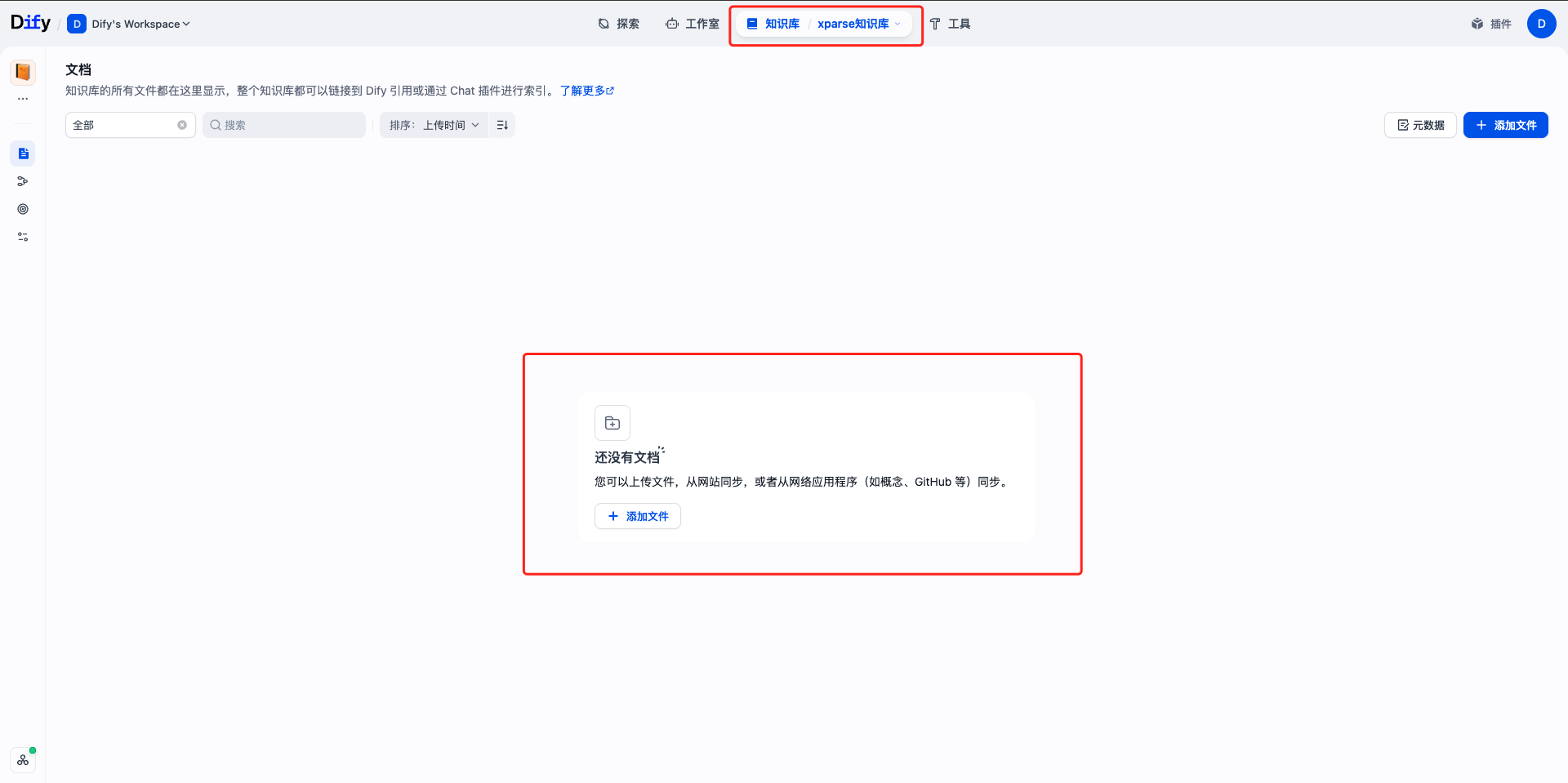
第七步:上传文档到知识库
知识流水线发布后,您可以开始上传文档。- 前往”知识库”页面
- 找到刚创建的”xparse知识库”
- 点击”上传文件”或”添加文件”
- 选择要上传的文档文件
- PDF 文档
- Word 文档(.docx)
- Excel 表格(.xlsx)
- PowerPoint 演示文稿(.pptx)
- 图片文件(JPG、PNG 等)
创建 Chatflow 演示应用
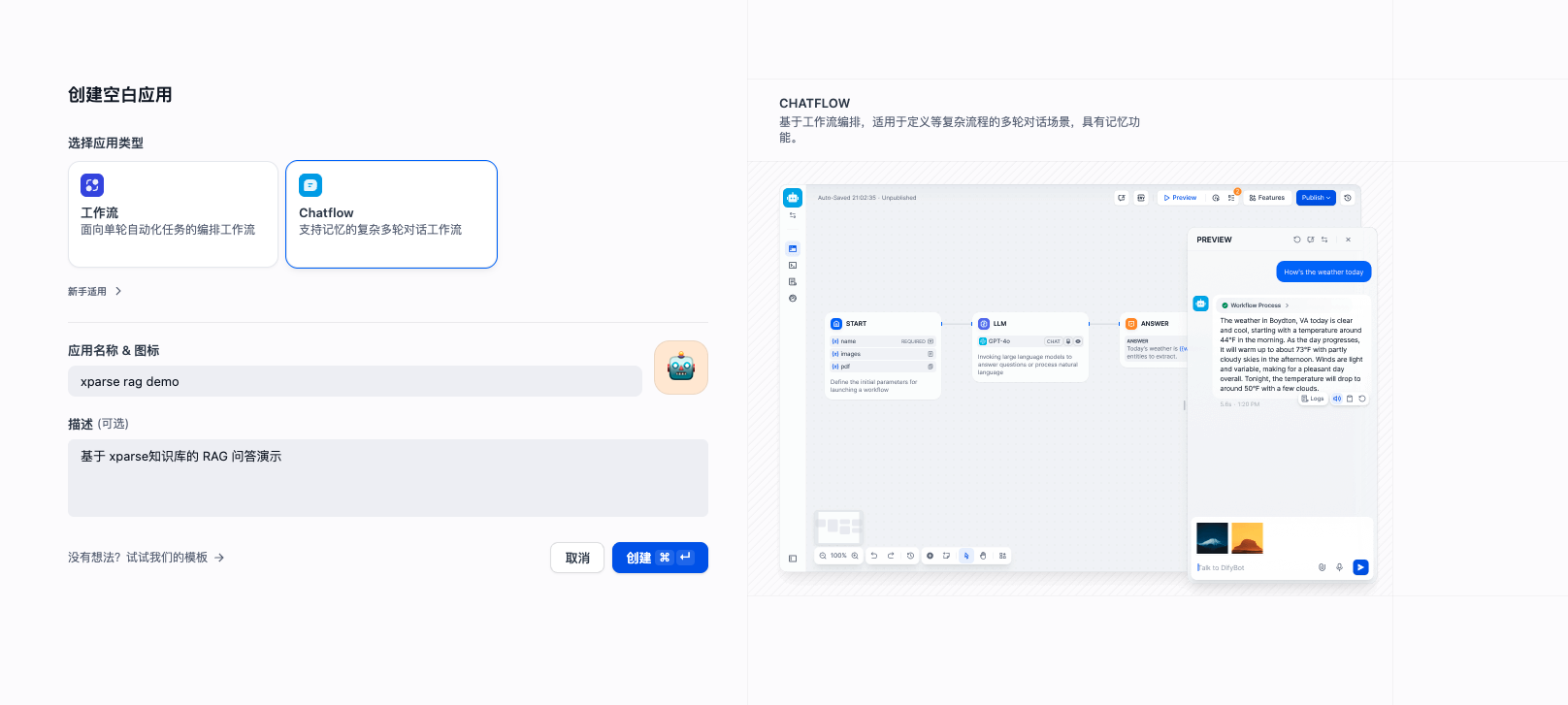
知识库创建完成后,我们将创建一个 Chatflow 应用来演示知识库的问答效果。第一步:创建 Chatflow 应用
- 在 Dify 平台中,进入”工作室”或”应用”页面,选择 “Chatflow”
- 点击”创建空白应用”
- 填写应用信息:
- 应用名称:如”xparse rag demo”
- 应用描述:如”基于 xparse知识库的 RAG 问答演示”
第二步:配置知识库检索节点
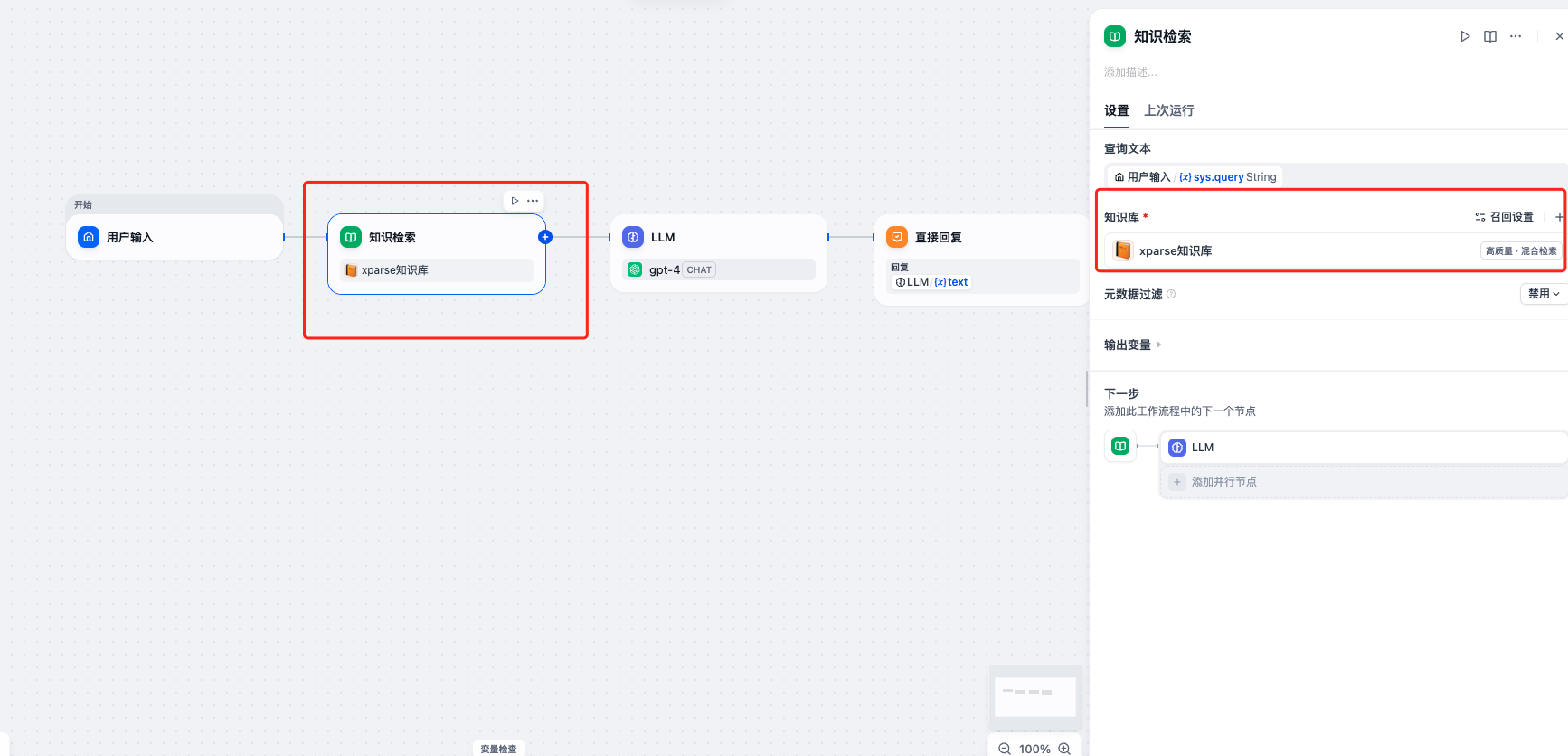
- 在 Chatflow 编辑器中,添加”知识检索”节点
- 配置检索参数:
- 知识库选择:选择已经创建好的知识库(如”xparse知识库”)
- 其他参数根据需要配置
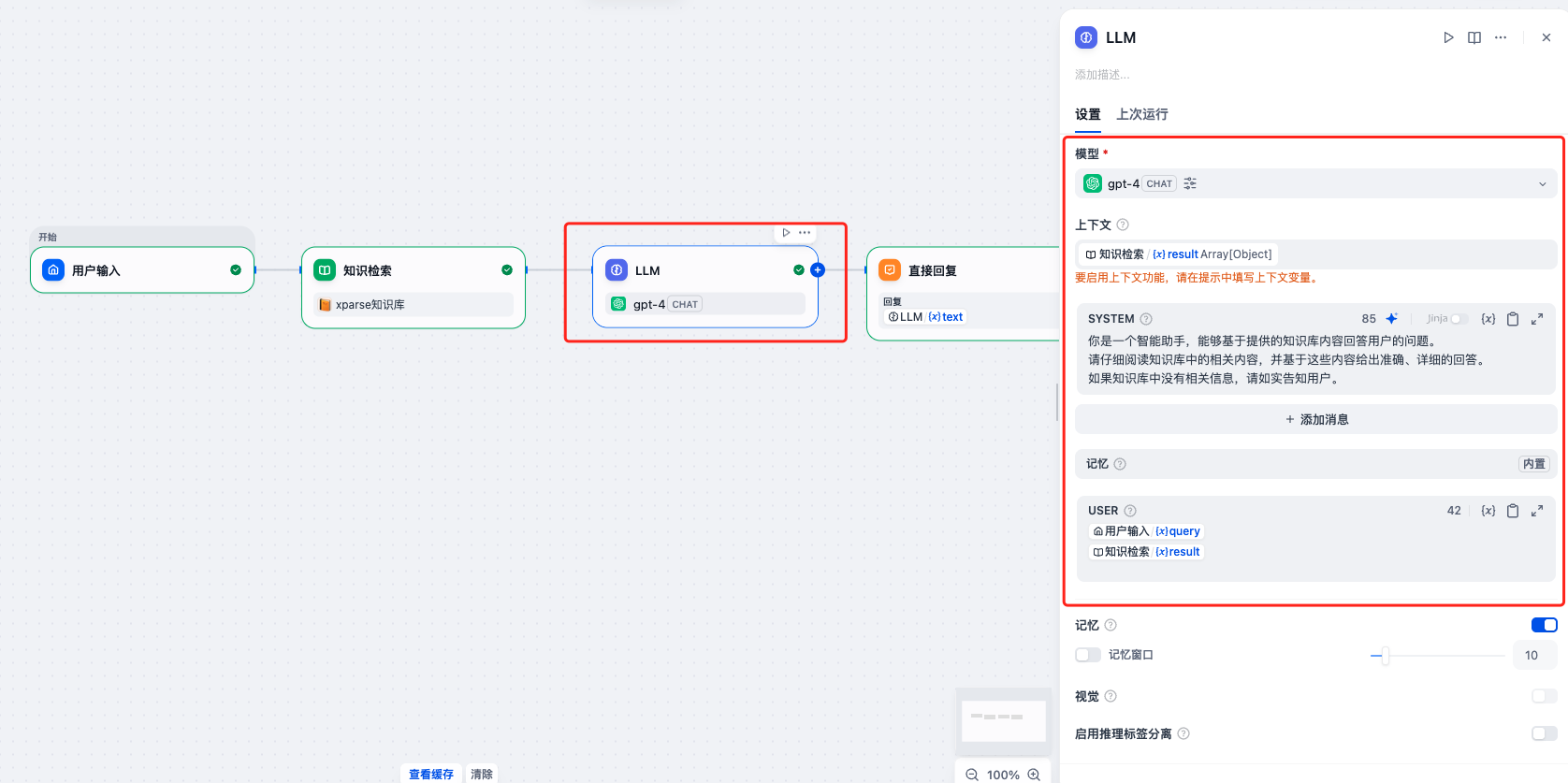
第三步:配置 LLM 节点
- 添加”LLM”节点
- 配置模型:
- 选择可用的 LLM 模型(如 GPT-4、Claude 等)
- 如果没有模型可用,需要先在插件市场安装对应的模型插件
- 配置上下文:
- 上下文:选择知识库检索节点的输出(通常是
result或context)
- 上下文:选择知识库检索节点的输出(通常是
- 配置系统提示词:
- 在”SYSTEM”区域填写提示词,例如:
- 在”SYSTEM”区域填写提示词,例如:
- 配置用户提示词
- 在”USER”区域增加上下文变量,例如:
知识检索 {result}
- 在”USER”区域增加上下文变量,例如:
第四步:连接节点
将各个节点按照以下顺序连接:- 开始节点 → 知识库检索节点
- 开始节点的用户输入传递给知识库检索节点
- 知识库检索节点 → LLM 节点
- 检索到的知识库内容作为上下文传递给 LLM
- LLM 节点 → 回复节点
- LLM 生成的回答返回给用户

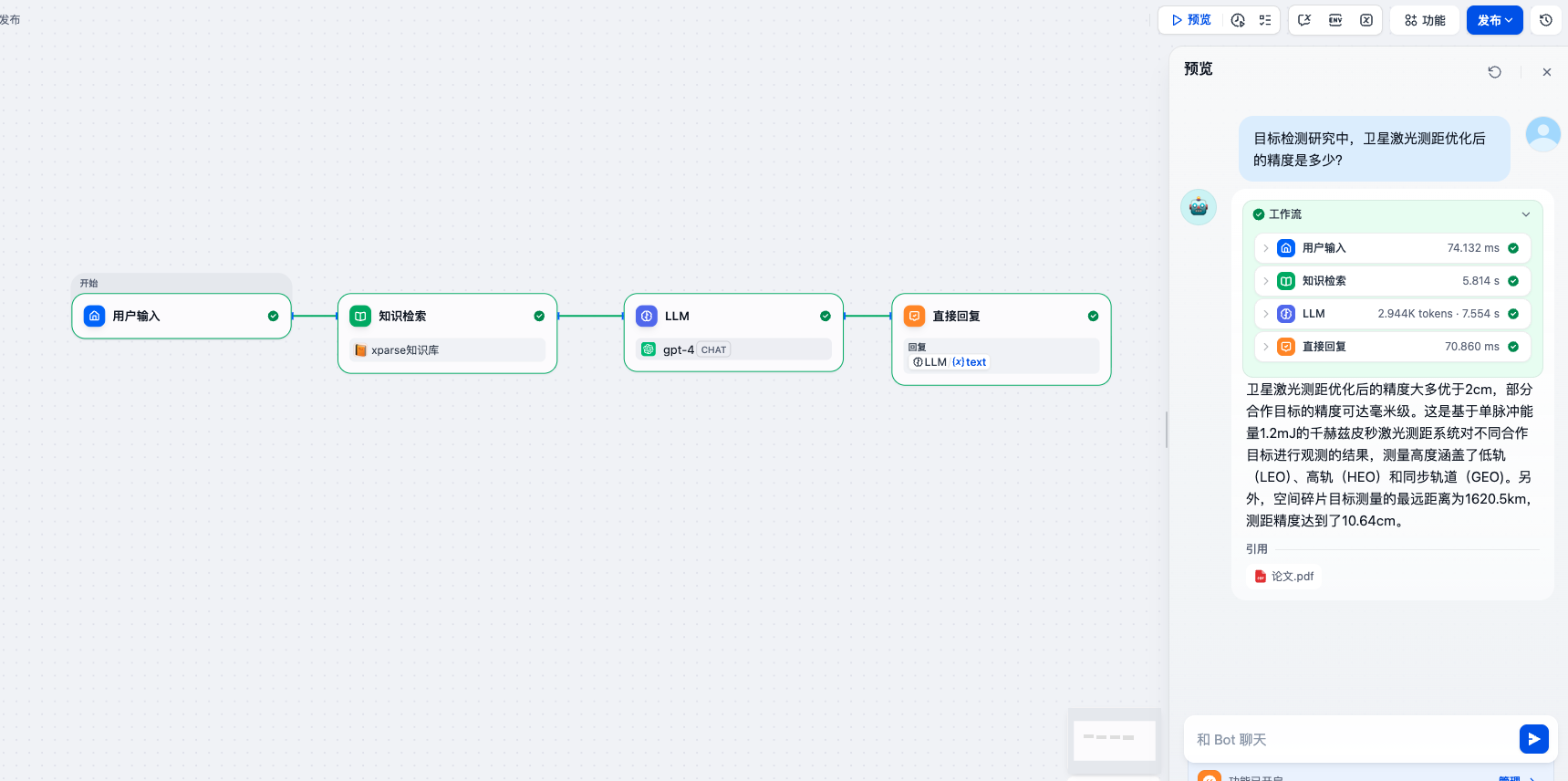
第五步:预览和测试
- 点击”预览”按钮,进入预览模式
- 在预览界面中输入问题,测试问答效果
- 观察以下内容:
- 知识库检索是否正常工作
- 检索到的内容是否相关
- LLM 生成的回答是否准确
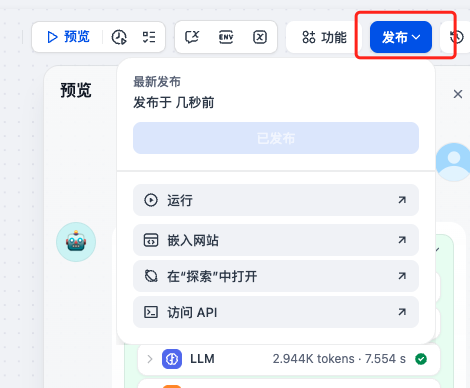
第六步:发布应用
测试通过后,可以发布应用供实际使用。- 点击”发布”或”保存并发布”按钮
- 发布成功后,可以通过 API 或 Web 界面访问应用
总结
通过本教程,您已经学会了:- 前置准备:获取 API Key、安装和配置 xParse Dify 插件
- 创建知识库:通过知识流水线创建知识库,配置数据源、xParse 解析、文本分块和知识库节点
- 创建 RAG 应用:通过 Chatflow 创建基于知识库的智能问答应用
- xParse 智能解析:准确提取文档内容,保留语义结构
- 父子文本分块:保持文档章节完整性,提升检索效果
- 混合检索:结合向量检索和关键词检索,提供更好的检索效果
- 快速搭建:通过 Dify 的可视化界面,快速构建 RAG 应用
常见问题
Q: 如何选择合适的解析引擎?
A:- Textin:适合大多数场景,速度和准确性俱佳(推荐)
- Textin Lite:适合纯文本、表格图片、电子档 PDF 等场景,速度更快,价格更低
- Mineru:适合学术论文等场景,表现优异
- PaddleOCR:适合多语言和复杂文档场景(如 PPT),表现优异
Q: 为什么选择父子文本分块?
A: 父子文本分块能够保持文档的章节结构,确保相关内容的完整性。这对于 RAG 应用非常重要,因为检索到的内容如果是完整的章节,能够提供更准确的上下文信息。Q: 混合检索和向量检索有什么区别?
A:- 向量检索:基于语义相似度进行检索,能够理解问题的语义含义
- 混合检索:结合向量检索和关键词检索,既能理解语义,又能精确匹配关键词,通常效果更好
Q: 如何优化检索效果?
A:- 确保文档解析质量:选择合适的解析引擎和预处理选项
- 优化分块策略:根据文档类型选择合适的分块策略
- 调整 Top K 值:根据实际效果调整返回的文档片段数量
- 优化系统提示词:让 LLM 更好地利用检索到的内容