一、为什么 Agent 需要专门的数据处理 workflow?
没有高质量的数据,Agent 就像没有记忆的大脑,无法做出准确的决策。
数据供给的四大挑战
构建一个 Demo 很容易,但构建一个生产级的 Agent 数据流非常困难。开发者通常会遇到”数据沼泽”: 挑战一:Source(数据源)极其分散 企业数据往往散落在各个角落:产品文档在 Notion,API 规范在 GitHub,销售记录在 Salesforce,历史合同在 S3 存储桶里的 PDF 中,客户反馈在 Slack 频道里。Agent 需要从这些异构系统中实时获取信息,但每个系统都有不同的认证方式、API 接口和数据格式。 挑战二:Format(格式)难以统一 不同格式的文档需要不同的解析策略:- PDF 的多栏排版、表格、图表、页眉页脚,简单的文本提取会丢失结构信息
- Excel 的复杂表格、公式、合并单元格,需要理解数据关系
- HTML 的嵌套标签、CSS 样式、JavaScript 动态内容,需要清洗无用信息
- Markdown 的图片引用、代码块、数学公式,需要保留语义结构
手动处理的成本陷阱
如果我们手动为每一个 Source 写脚本,维护成本将是灾难性的:- 每个数据源都需要编写专门的连接器
- 每种格式都需要定制解析逻辑
- 每次源系统更新 API,都需要修改代码
- 数据同步失败时,需要人工排查和修复
二、 解决方案:端到端的智能数据流水线
xParse workflow:连接数据与 Agent 的桥梁
我们的产品旨在解决这一核心痛点,提供一个从原始数据到 Agent 可用知识的自动化工作流。它将复杂的非结构化数据处理过程抽象为标准的 ETL 流程(Extract, Transform, Load),让开发者无需关心底层的数据处理细节,专注于 Agent 的业务逻辑。五步走:从混乱到有序
1. Connect & Ingest (多源接入)
解决的问题:数据源分散、格式各异 不仅是简单的文件上传,而是建立多功能连接器。xParse workflow 支持以下数据源与协议:- 本地文件系统:支持丰富的文件类型,包括但不限于PDF、图片、Office文档等
- 远程文件系统:FTP、SMB等协议
- 云存储:S3、OSS、COS 等
2. Intelligent Parsing (智能解析)
解决的问题:格式混乱、结构丢失 这是最关键的一步。简单的text.read() 远远不够,我们需要理解文档的语义结构:
-
对于 PDF:
- 进行 OCR 识别扫描件中的文字
- 布局分析识别标题、段落、表格、图表、页眉页脚
- 避免将页码、水印误读为正文
- 保留表格的结构化信息,转换为 Markdown 表格格式
-
对于 HTML:
- 清洗无用的 CSS/JS,仅保留语义内容
- 识别文章主体,过滤导航栏、广告等噪音
- 保留链接关系,便于构建知识图谱
-
对于 Excel:
- 识别表头、数据行、公式
- 处理合并单元格、多工作表
- 提取数据关系,生成结构化描述
- 等等
3. Semantic Chunking (语义分块)
解决的问题:上下文窗口限制、语义切断 简单的按字符数切分(例如每 500 字切一刀)会切断语义,导致检索失败。我们的 xParse workflow 支持更高级的策略:- 根据页面切分(by_page):尽可能在段落、句子边界切分,保持语义完整性
- 基于结构的切分(by_title):按 Markdown 标题层级切分,每个章节作为一个 Chunk
- 语义相似度切分(by_similarity):通过滑动窗口计算前后文相似度,在语义突变点切分
4. Embedding (向量化)
解决的问题:语义理解、相似度计算 将切分好的 Chunk 转换为机器可理解的向量(Vectors)。产品支持:- 多种 Embedding 模型:集成Qwen、火山引擎等多家主流服务商
- 维度配置:支持自定义维度配置,与下游更好地对接
- 批量处理:高效的批量向量化,支持大规模数据处理
5. Sync to Destinations (写入多目标)
解决的问题:实时同步、多场景支持 处理好的向量和元数据(Metadata)可以被推送到不同的目的地,服务于不同的 Agent 场景:-
向量数据库(Pinecone, Milvus, Weaviate, Qdrant):
- 用于高并发的语义检索
- 支持相似度搜索、混合搜索(语义+关键词)
- 适合 RAG 场景
-
全文搜索引擎(Elasticsearch, OpenSearch):
- 用于关键词匹配、模糊搜索
- 支持复杂的查询语法
- 适合精确匹配场景
-
图数据库(Neo4j, ArangoDB):
- 用于构建知识图谱(GraphRAG)
- 支持实体关系查询
- 适合需要理解数据关系的场景
xParse workflow 如何解决 Agent 的数据难题
通过上述五步流程,xParse workflow 系统性地解决了 Agent 面临的数据挑战:- 统一接入:无论数据来自哪里,都通过统一的接口接入,Agent 无需关心数据源
- 智能解析:自动识别和处理各种格式,提取结构化信息
- 语义分块:确保每个 Chunk 都是语义完整的,提高检索准确率
- 高效检索:通过向量化和多目标同步,支持快速、准确的语义检索
- 实时更新:定时执行任务,确保 Agent 始终使用最新数据
三、 架构概览:xParse workflow 如何赋能 Agent
以下展示了我们的产品如何作为中间件,连接原始数据与 AI Agent: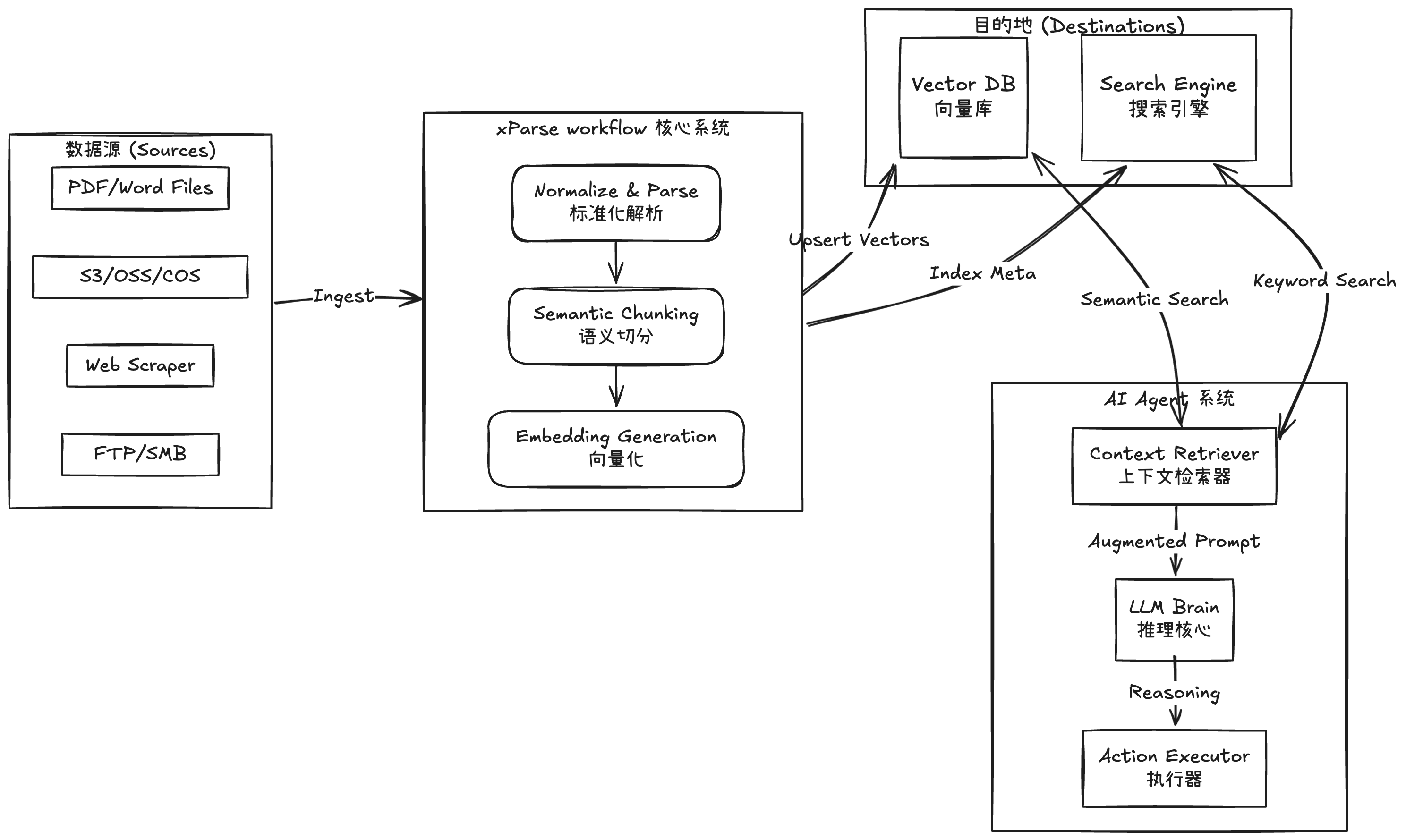
流程解析:数据如何从混乱到有序
上游(数据采集): 全量与增量两种模式,文档更新可以及时重新进行处理且尽量减少开支 中游(数据处理): 数据流经 xParse workflow 系统,经历三个关键转换:- 标准化解析:原本杂乱的 PDF、Excel、HTML 被统一转换为结构化的文本
- 语义切分:长文档被智能切分为语义完整的 Chunk
- 向量化:文本被转换为高维向量,携带丰富的元数据(Metadata)
Knowledge_Base,以多种形式存储:
- 向量形式存储在向量数据库中,支持快速语义检索
- 元数据和全文索引存储在搜索引擎中,支持关键词匹配
AI_Agent 不再需要关心:
- 数据是从哪里来的(S3?FTP?本地?)
- 数据是什么格式的(PDF?Excel?Markdown?)
- 数据是如何解析的(OCR?布局分析?)
Destinations 发起查询,即可获得最精准的上下文。xParse workflow 系统将复杂的数据处理过程完全抽象,让 Agent 专注于推理和决策。
四、 总结:xParse workflow 是 Agent 的”大脑皮层”
数据质量决定 Agent 智能上限
回顾本文的核心观点:- AI Agent 的强大能力建立在数据之上:无论是智能客服、代码审查、数据分析还是知识管理,Agent 都需要从高质量的数据中获取知识。
- 数据供给是最大的瓶颈:企业数据分散、格式混乱、更新频繁,手动处理成本高昂且难以维护。
- xParse workflow 是解决问题的关键:通过标准化的 ETL 流程,将非结构化数据转换为 Agent 可用的知识,让 Agent 专注于推理和决策。
从 Demo 到生产:xParse workflow 的价值
构建 Agent 的逻辑代码可能只需要几天:- 调用 LLM API
- 实现 RAG 检索
- 设计 Prompt 模板
- 集成工具调用
- 支持 20+ 种数据源连接
- 处理 10+ 种文件格式解析
- 实现智能语义分块
- 保证数据实时同步
- 处理异常和错误恢复
让 Agent 从”玩具”走向”生产环境”
利用我们的 xParse workflow 产品,开发者可以:- 专注于业务逻辑:将精力集中在 Agent 的 Prompt 调优、工具设计、业务规则上
- 降低维护成本:无需为每个数据源编写脚本,无需处理格式解析的细节
- 提高数据质量:通过标准化的处理流程,确保 Agent 始终使用最新、最准确的数据
- 加速迭代速度:快速接入新的数据源,快速调整处理策略,快速验证 Agent 效果