推荐使用 Python SDK 快速上手。如果您更熟悉直接调用 REST API,可参考下方 REST API 示例。 新版本核心升级
相比旧版文档解析,新版本带来以下核心改进:
更轻量的数据结构
采用标准化的 Element 模型,数据结构更简洁清晰,易于理解和使用。返回的 JSON 体积更小,传输更快。
标准输入输出协议
统一的请求配置(Config)和响应结构(Schema),兼容多种解析引擎,便于集成和迁移。
引擎可替换
支持多种解析引擎(TextIn 和 GUI),可根据场景选择最优引擎,或对比不同引擎效果。
异步 API 支持
新增异步解析接口,支持大文件和批量处理场景,避免 HTTP 超时。支持 Webhook 回调,无需轮询。
新增 GUI 识别引擎,精准解析界面元素专门用于识别桌面、移动应用和网页截图,返回 UI 元素类型(按钮、输入框、复选框等)及其位置、文本、交互性等信息。解析效果如下: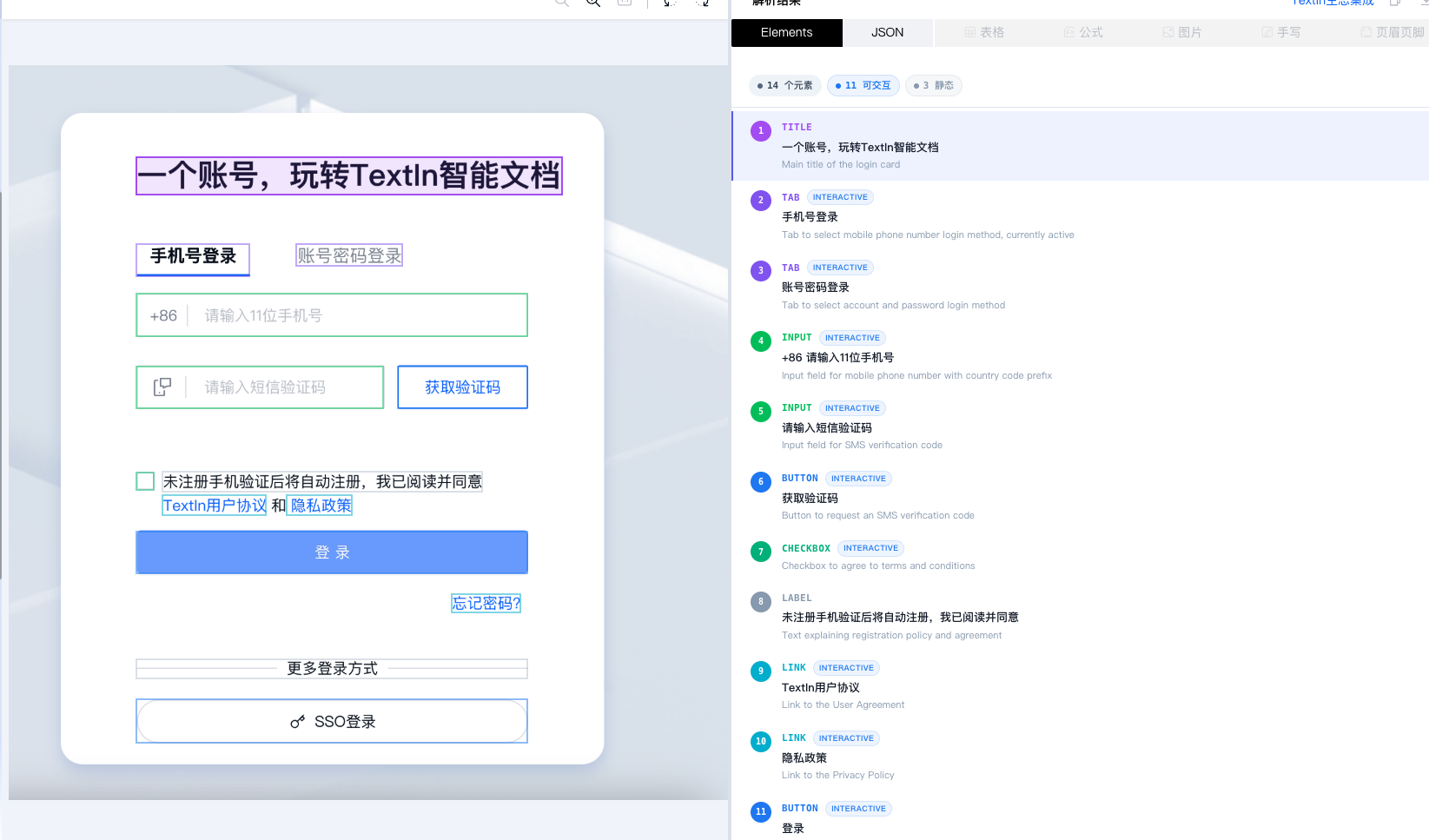 了解更多:GUI 引擎配置详解
了解更多:GUI 引擎配置详解
准备工作
1. 获取 API Key
前往 TextIn 工作台 - 账号与开发者信息 获取您的 x-ti-app-id 和 x-ti-secret-code。
详细步骤请参考 API Key 获取指南。
2. 准备示例文件
您可以使用自己的文档,或下载我们提供的示例文件:文档解析示例.pdf
支持的文件格式:png, jpg, jpeg, pdf, bmp, tiff, webp, doc, docx, html, mhtml, xls, xlsx, csv, ppt, pptx, txt, ofd, rtf文件大小限制:500MB
使用 Python SDK(推荐)
Step 1:安装 SDK
pip install xparse-client
Step 2:配置环境变量
export TEXTIN_APP_ID="your-app-id"
export TEXTIN_SECRET_CODE="your-secret-code"
Step 3:解析文档
from xparse_client import XParseClient, ParseConfig, Capabilities
# 初始化客户端(自动读取环境变量)
client = XParseClient()
# 解析本地文件
with open("document.pdf", "rb") as f:
result = client.parse.run(
file=f,
filename="document.pdf",
config=ParseConfig(
capabilities=Capabilities(
include_table_structure=True,
title_tree=True,
),
),
)
上面的示例使用了简单的配置。你可以通过 ParseConfig 自定义更多能力,如字符详情、行内对象、图片数据等。详见 解析配置详解。 Step 4:查看结果
# 输出 Markdown
if result.markdown:
print(result.markdown)
# 遍历文档元素
for el in result.elements:
print(f"[{el.type}] {el.text[:80]}")
print(f"共解析 {len(result.elements)} 个元素")
Step 5:保存结果
import json
# 保存为 Markdown 文件
with open("output.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
# 保存完整 JSON 结果
with open("output.json", "w", encoding="utf-8") as f:
json.dump(result.model_dump(), f, ensure_ascii=False, indent=2)
完整代码(一键运行)
"""
用法:
1. 安装依赖: pip install xparse-client
2. 设置环境变量 TEXTIN_APP_ID 和 TEXTIN_SECRET_CODE
3. python quickstart.py <文件路径>
"""
import json
import sys
from pathlib import Path
from xparse_client import XParseClient, ParseConfig, Capabilities
def main():
# 从命令行参数获取文件路径,默认使用 document.pdf
file_path = Path(sys.argv[1]) if len(sys.argv) > 1 else Path("document.pdf")
if not file_path.exists():
print(f"文件不存在: {file_path}")
sys.exit(1)
# Step 1: 初始化客户端(自动读取环境变量 TEXTIN_APP_ID, TEXTIN_SECRET_CODE)
client = XParseClient()
# Step 2: 解析文档
with open(file_path, "rb") as f:
result = client.parse.run(
file=f,
filename=file_path.name,
config=ParseConfig(
capabilities=Capabilities(
include_table_structure=True,
title_tree=True,
),
),
)
# Step 3: 打印解析概览
print(f"解析完成!共 {len(result.elements)} 个元素,{result.success_count} 页成功")
print("=" * 60)
# 输出 Markdown
if result.markdown:
print(result.markdown[:2000])
if len(result.markdown) > 2000:
print(f"\n... (Markdown 共 {len(result.markdown)} 字符,已截断)")
print("=" * 60)
# 遍历文档元素
for el in result.elements:
print(f" [{el.type:20s}] p{el.page_number}: {el.text[:60]}")
# Step 4: 保存结果
output_dir = Path("output")
output_dir.mkdir(exist_ok=True)
stem = file_path.stem
md_path = output_dir / f"{stem}.md"
with open(md_path, "w", encoding="utf-8") as f:
f.write(result.markdown)
print(f"\nMarkdown 已保存: {md_path}")
json_path = output_dir / f"{stem}.json"
with open(json_path, "w", encoding="utf-8") as f:
json.dump(result.model_dump(), f, ensure_ascii=False, indent=2)
print(f"JSON 已保存: {json_path}")
if __name__ == "__main__":
main()
REST API 示例
如果您不使用 Python SDK,可以直接调用 REST API。
同步解析
import requests
import json
app_id = "your-app-id"
secret_code = "your-secret-code"
with open("document.pdf", "rb") as f:
response = requests.post(
"https://api.textin.com/api/v1/xparse/parse/sync",
headers={
"x-ti-app-id": app_id,
"x-ti-secret-code": secret_code,
},
files={"file": ("document.pdf", f)},
data={
"config": json.dumps({
"capabilities": {
"include_table_structure": True,
"title_tree": True
}
})
},
)
result = response.json()
print(result["data"]["markdown"])
config 参数支持丰富的配置选项,包括层级关系、字符详情、行内对象、图片数据等。完整配置说明请参考 解析配置详解。异步解析(适用于大文件)
对于大文件或需要批量处理的场景,建议使用异步 API:
import requests
import json
import time
app_id = "your-app-id"
secret_code = "your-secret-code"
headers = {
"x-ti-app-id": app_id,
"x-ti-secret-code": secret_code,
}
# Step 1: 创建异步任务
with open("large_document.pdf", "rb") as f:
response = requests.post(
"https://api.textin.com/api/v1/xparse/parse/async",
headers=headers,
files={"file": ("large_document.pdf", f)},
)
job_id = response.json()["data"]["job_id"]
print(f"任务已创建: {job_id}")
# Step 2: 轮询查询任务状态
while True:
status_resp = requests.get(
f"https://api.textin.com/api/v1/xparse/parse/async/{job_id}",
headers=headers,
)
status_data = status_resp.json()["data"]
if status_data["status"] == "completed":
print("解析完成!")
print(status_data)
# Step 3: 通过 result_url 获取实际结果
result_url = status_data["result_url"]
result_resp = requests.get(result_url, headers=headers)
result_data = result_resp.json()
# 输出元素信息
print(f"共解析 {len(result_data['elements'])} 个元素")
for element in result_data["elements"][:5]:
print(f"[{element['type']}] {element['text'][:50]}")
break
elif status_data["status"] == "failed":
print(f"解析失败: {status_data.get('message', '未知错误')}")
break
print(f"状态: {status_data['status']},等待中...")
time.sleep(5)
理解返回结果
解析成功后,返回的核心数据结构如下:
{
"code": 200,
"message": "success",
"data": {
"schema_version": "1.3.0",
"file_id": "doc_7f3a2b",
"job_id": "job_x9k2m",
"success_count": 5,
"metadata": {
"filename": "document.pdf",
"filetype": "application/pdf",
"page_count": 5,
"data_source": {
"record_locator": {
"protocol": "file",
"remote_file_path": "/path/to/document.pdf"
},
"url": "file:///path/to/document.pdf"
}
},
"markdown": "# 文档标题\n\n这是正文内容...\n\n| 列1 | 列2 |\n|---|---|\n| 值1 | 值2 |",
"elements": [
{
"element_id": "el_001",
"type": "Title",
"text": "文档标题",
"page_number": 1,
"coordinates": [0.100000, 0.120000, 0.320000, 0.120000, 0.320000, 0.160000, 0.100000, 0.160000],
"metadata": {
"category_depth": 0,
"children_ids": ["el_002"],
"is_continuation": false,
"data_source": {
"record_locator": {
"protocol": "file",
"remote_file_path": "/path/to/document.pdf"
},
"url": "file:///path/to/document.pdf"
}
}
},
{
"element_id": "el_002",
"type": "NarrativeText",
"text": "这是正文内容...",
"page_number": 1,
"coordinates": [0.100000, 0.180000, 0.900000, 0.180000, 0.900000, 0.220000, 0.100000, 0.220000],
"metadata": {
"parent_id": "el_001",
"is_continuation": false,
"data_source": {
"record_locator": {
"protocol": "file",
"remote_file_path": "/path/to/document.pdf"
},
"url": "file:///path/to/document.pdf"
}
}
}
]
}
}
| 字段 | 说明 |
|---|
schema_version | 数据结构版本号,当前为 "1.3.0" |
file_id | 文件唯一标识 |
job_id | 任务唯一标识 |
success_count | 成功解析的页数(计费依据) |
metadata | 文件元信息(文件名、类型、页数、数据源等) |
markdown | 文档的 Markdown 表示,可直接用于 LLM 输入 |
elements | 文档元素列表,每个元素包含类型、文本、坐标、元信息等详细信息 |
下一步
解析配置详解
深入了解所有输入参数配置,包括能力开关、处理范围、引擎选择等
返回结构详解
了解 Elements、坐标、表格结构等完整返回字段
Python SDK
SDK 高级用法:异步任务、错误处理、自定义配置