多并发测试
您可以先参考以下示例代码进行文档解析API的多并发请求测试。import concurrent.futures
import subprocess
import time
# 要测试的命令
CMD = [
"python3",
"用于跑示例的请求脚本.py" # 替换为你用于测试的请求脚本,也可以使用下文提供的脚本进行测试
]
# 并发数
CONCURRENCY = 5
# 总测试次数
TOTAL_RUNS = 5
def run_cmd(i):
try:
result = subprocess.run(CMD, capture_output=True, text=True, check=True)
print(f"任务 {i} 成功,输出:{result.stdout.strip()}")
except subprocess.CalledProcessError as e:
print(f"任务 {i} 失败,错误:{e.stderr.strip()}")
if __name__ == "__main__":
print(f'并发测试,当前并发数为: {CONCURRENCY}')
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=CONCURRENCY) as executor:
futures = [executor.submit(run_cmd, i) for i in range(TOTAL_RUNS)]
concurrent.futures.wait(futures)
end_time = time.time()
print(f"程序总耗时:{end_time - start_time:.2f} 秒")
这里使用快速启动中的示例文件进行多并发测试:文档解析pdf示例.pdf
- 测试脚本如下:参考快速启动,解析位于URL的文件并保存结果;需替换您自己的 x-ti-app-id 和 x-ti-secret-code
注意:进行多并发测试等同对当前账号发起线上资源操作,请留意费用情况,请小心操作。
import json
import requests
class OCRClient:
def __init__(self, app_id: str, secret_code: str):
self.app_id = app_id
self.secret_code = secret_code
def recognize(self, file_content: bytes, options: dict) -> str:
# 构建请求参数
params = {}
for key, value in options.items():
params[key] = str(value)
# 设置请求头
headers = {
"x-ti-app-id": self.app_id,
"x-ti-secret-code": self.secret_code,
# 方式一:读取本地文件
# "Content-Type": "application/octet-stream"
# 方式二:使用URL方式
"Content-Type": "text/plain"
}
# 发送请求
response = requests.post(
f"https://api.textin.com/ai/service/v1/pdf_to_markdown",
params=params,
headers=headers,
data=file_content
)
# 检查响应状态
response.raise_for_status()
return response.text
def main():
# 创建客户端实例,需替换为你的API Key
client = OCRClient("你的x-ti-app-id", "你的x-ti-secret-code")
# 文件URL,这里为你提供了一份真实可用的示例URL
file_content = "https://dllf.intsig.net/download/2025/Solution/textin/sample/pdf_to_markdown/sample_02.pdf"
# 设置URL参数,可按需设置,这里已为你默认设置了一些参数
options = dict(
dpi=144,
get_image="objects",
markdown_details=1,
page_count=10,
parse_mode="auto",
table_flavor="html"
)
import time
# 在发送请求前记录开始时间
start_time = time.time()
try:
response = client.recognize(file_content, options)
# 保存完整的JSON响应到result.json文件
with open("result.json", "w", encoding="utf-8") as f:
f.write(response)
# 解析JSON响应以提取markdown内容
json_response = json.loads(response)
if "result" in json_response and "markdown" in json_response["result"]:
markdown_content = json_response["result"]["markdown"]
with open("result.md", "w", encoding="utf-8") as f:
f.write(markdown_content)
# 记录请求结束时间
end_time = time.time()
print(f"请求耗时:{end_time - start_time:.2f} 秒")
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
main()
- 多并发测试结果如下图:可以看到文档解析API支持多并发请求,并且可以极大程度上节省时间。我们始终贯彻“您只需关心业务,剩下的文档解析处理工作交给TextIn”的理念,希望尽一切可能为您的业务发展提供帮助。
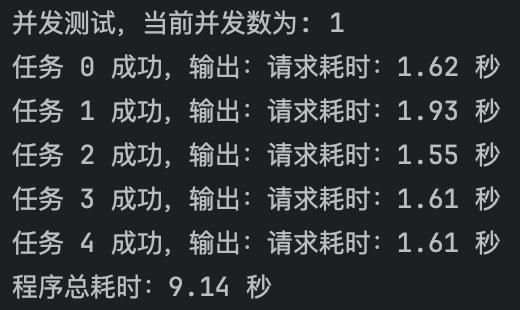
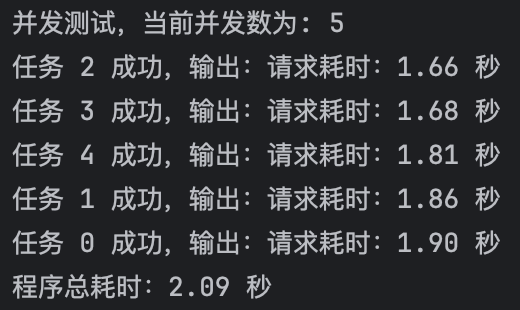
多并发请求
当您想要进行文档解析API的多并发请求时,以下是一份完整的示例代码供您参考,您也可以根据实际使用需要进行修改调整。import os
import json
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
class OCRClient:
def __init__(self, app_id: str, secret_code: str):
self.app_id = app_id
self.secret_code = secret_code
def recognize(self, file_content: bytes, options: dict) -> str:
params = {key: str(value) for key, value in options.items()}
headers = {
"x-ti-app-id": self.app_id,
"x-ti-secret-code": self.secret_code,
"Content-Type": "application/octet-stream"
}
response = requests.post(
"https://api.textin.com/ai/service/v1/pdf_to_markdown",
params=params,
headers=headers,
data=file_content
)
response.raise_for_status()
return response.text
def process_file(client: OCRClient, file_path: str, output_dir: str, options: dict):
filename = os.path.basename(file_path)
try:
with open(file_path, "rb") as f:
file_content = f.read()
response = client.recognize(file_content, options)
base_name = os.path.splitext(filename)[0]
# 保存JSON
with open(os.path.join(output_dir, f"{base_name}.json"), "w", encoding="utf-8") as fw:
fw.write(response)
# 保存Markdown
json_response = json.loads(response)
if "result" in json_response and "markdown" in json_response["result"]:
markdown_content = json_response["result"]["markdown"]
with open(os.path.join(output_dir, f"{base_name}.md"), "w", encoding="utf-8") as fw:
fw.write(markdown_content)
print(f"{filename} 处理完成")
except Exception as e:
print(f"{filename} 处理出错: {e}")
def main():
client = OCRClient("你的x-ti-app-id", "你的x-ti-secret-code")
input_dir = "./tmp" # 你的待解析文件夹
output_dir = "./output" # 输出结果的文件夹
os.makedirs(output_dir, exist_ok=True)
exts = (".pdf",".png",".jpg",".jpeg",".bmp",".tiff",".webp",".doc",".docx",".html",".mhtml",".xls",".xlsx",".csv",".ppt",".pptx",".txt",".ofd",".rtf")
files = [f for f in os.listdir(input_dir) if f.lower().endswith(exts)]
file_paths = [os.path.join(input_dir, f) for f in files]
# 设置URL参数,可按需设置,这里已为你默认设置了一些参数
options = dict(
dpi=144,
get_image="objects",
markdown_details=1,
page_count=10,
parse_mode="auto",
table_flavor="html"
)
# 设置并发数
max_workers = 5 # 你可以根据需要调整并发数
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [
executor.submit(process_file, client, file_path, output_dir, options)
for file_path in file_paths
]
for future in as_completed(futures):
# 这里可以捕获每个任务的异常
try:
future.result()
except Exception as exc:
print(f"任务出错: {exc}")
if __name__ == "__main__":
main()