- 设置URL参数image-output-type为base64str,此时图片直接以base64格式在API结果中返回。(这种方式返回结果体积会很大,长文档不推荐)
- 设置URL参数image-output-type为default(不传时默认为该值),此时图片直接以TextIn平台的链接方式返回,您可以通过链接下载图片到本地,或上传到您的云存储。
如何将markdown中的图片链接替换为本地图片链接
您可以参考如下教程:使用上述方法2让API返回图片链接,并完成markdown中的图片链接替换。这里为您提供了一份Textin官方pdf示例文件,您可点击下载或使用该链接:文档解析pdf示例.pdf
- 参考快速启动,在 options 中设置参数 get_image 为 objects 或 both,让API返回页面内的图片对象;设置参数 image_output_type 为 default,API会返回图片URL。如下图:
- 参考如下示例代码:提取返回结果markdown中的图片URL将图片下载保存至本地,并将markdown中的图片链接替换为本地图片链接。
import os
import re
import requests
import hashlib
from urllib.parse import urlparse
from pathlib import Path
import time
from typing import List, Tuple, Optional
class ImageDownloader:
def __init__(self, md_file: str, images_dir: str = "images"):
"""
初始化图片下载器
Args:
md_file: markdown文件路径
images_dir: 图片存储目录
"""
self.md_file = md_file
self.images_dir = images_dir
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
})
# 创建图片目录
Path(self.images_dir).mkdir(exist_ok=True)
def extract_image_urls(self, content: str) -> List[Tuple[str, str]]:
"""
提取markdown内容中的图片链接
Args:
content: markdown文件内容
Returns:
(完整的markdown语法, 图片URL) 的元组列表
"""
# 匹配  格式的markdown图片语法
pattern = r'!\[([^\]]*)\]\((https://[^\s\)]+\.(?:jpg|jpeg|png|gif|bmp|webp|svg))\)'
matches = re.findall(pattern, content, re.IGNORECASE)
# 返回完整的markdown语法和URL
result = []
for alt_text, url in matches:
full_markdown = f""
result.append((full_markdown, url))
return result
def generate_filename(self, url: str) -> str:
"""
根据URL生成本地文件名
Args:
url: 图片URL
Returns:
本地文件名
"""
# 解析URL获取文件名
parsed_url = urlparse(url)
original_filename = os.path.basename(parsed_url.path)
# 如果没有扩展名,从URL中提取
if not original_filename or '.' not in original_filename:
# 使用URL的MD5哈希作为文件名
url_hash = hashlib.md5(url.encode()).hexdigest()[:12]
original_filename = f"{url_hash}.jpg" # 默认为jpg
return original_filename
def download_image(self, url: str, max_retries: int = 3) -> Optional[str]:
"""
下载单个图片
Args:
url: 图片URL
max_retries: 最大重试次数
Returns:
成功时返回本地文件路径,失败时返回None
"""
filename = self.generate_filename(url)
local_path = os.path.join(self.images_dir, filename)
# 如果文件已存在,跳过下载
if os.path.exists(local_path):
print(f"📁 文件已存在: {local_path}")
return local_path
for attempt in range(max_retries):
try:
print(f"⬇️ 正在下载 ({attempt + 1}/{max_retries}): {url}")
response = self.session.get(url, timeout=30)
response.raise_for_status()
# 检查是否是图片文件
content_type = response.headers.get('content-type', '')
if not content_type.startswith('image/'):
print(f"⚠️ 警告: {url} 不是图片文件 (Content-Type: {content_type})")
# 保存文件
with open(local_path, 'wb') as f:
f.write(response.content)
file_size = len(response.content)
print(f"✅ 下载成功: {filename} ({file_size} bytes)")
return local_path
except requests.exceptions.RequestException as e:
print(f"❌ 下载失败 (尝试 {attempt + 1}/{max_retries}): {e}")
if attempt < max_retries - 1:
time.sleep(2) # 重试前等待2秒
else:
print(f"💀 下载彻底失败: {url}")
return None
return None
def process_markdown(self) -> bool:
"""
处理markdown文件,下载图片并替换链接
Returns:
处理是否成功
"""
try:
# 读取markdown文件
with open(self.md_file, 'r', encoding='utf-8') as f:
content = f.read()
# 备份原文件
backup_file = f"{self.md_file}.backup"
with open(backup_file, 'w', encoding='utf-8') as f:
f.write(content)
print(f"🗂️ 已创建备份文件: {backup_file}")
# 提取图片链接
image_data = self.extract_image_urls(content)
if not image_data:
print("🔍 未找到图片链接")
return True
print(f"🔍 找到 {len(image_data)} 个图片链接")
# 下载图片并替换链接
replacements = []
for i, (markdown_syntax, url) in enumerate(image_data, 1):
print(f"\n📋 处理第 {i}/{len(image_data)} 个链接:")
print(f"🔍 原始语法: {markdown_syntax}")
local_path = self.download_image(url)
if local_path:
# 使用相对路径
relative_path = os.path.relpath(local_path, os.path.dirname(self.md_file))
# 保留原始的alt text,只替换URL
alt_text = re.search(r'!\[([^\]]*)\]', markdown_syntax).group(1)
new_markdown = f""
replacements.append((markdown_syntax, new_markdown))
print(f"🔗 将替换为: {new_markdown}")
else:
print(f"⚠️ 保留原始链接: {markdown_syntax}")
# 应用替换
modified_content = content
for old_link, new_link in replacements:
modified_content = modified_content.replace(old_link, new_link)
# 保存修改后的文件
with open(self.md_file, 'w', encoding='utf-8') as f:
f.write(modified_content)
print(f"\n✅ 处理完成!")
print(f"📊 成功替换 {len(replacements)} 个链接")
print(f"📁 图片保存在: {self.images_dir}/")
print(f"📄 原文件备份: {backup_file}")
return True
except Exception as e:
print(f"❌ 处理失败: {e}")
return False
def cleanup(self):
"""清理资源"""
self.session.close()
def main():
"""主函数"""
print("🚀 图片下载器启动")
print("=" * 50)
# 配置
md_file = "test.md" # 这里替换为你的markdown文件路径
images_dir = "images" # 这里替换为你的图片存储目录
# 检查文件是否存在
if not os.path.exists(md_file):
print(f"❌ 文件不存在: {md_file}")
return
# 创建下载器并处理
downloader = ImageDownloader(md_file, images_dir)
try:
success = downloader.process_markdown()
if success:
print("\n🎉 所有操作完成!")
else:
print("\n💥 操作失败!")
finally:
downloader.cleanup()
if __name__ == "__main__":
main()
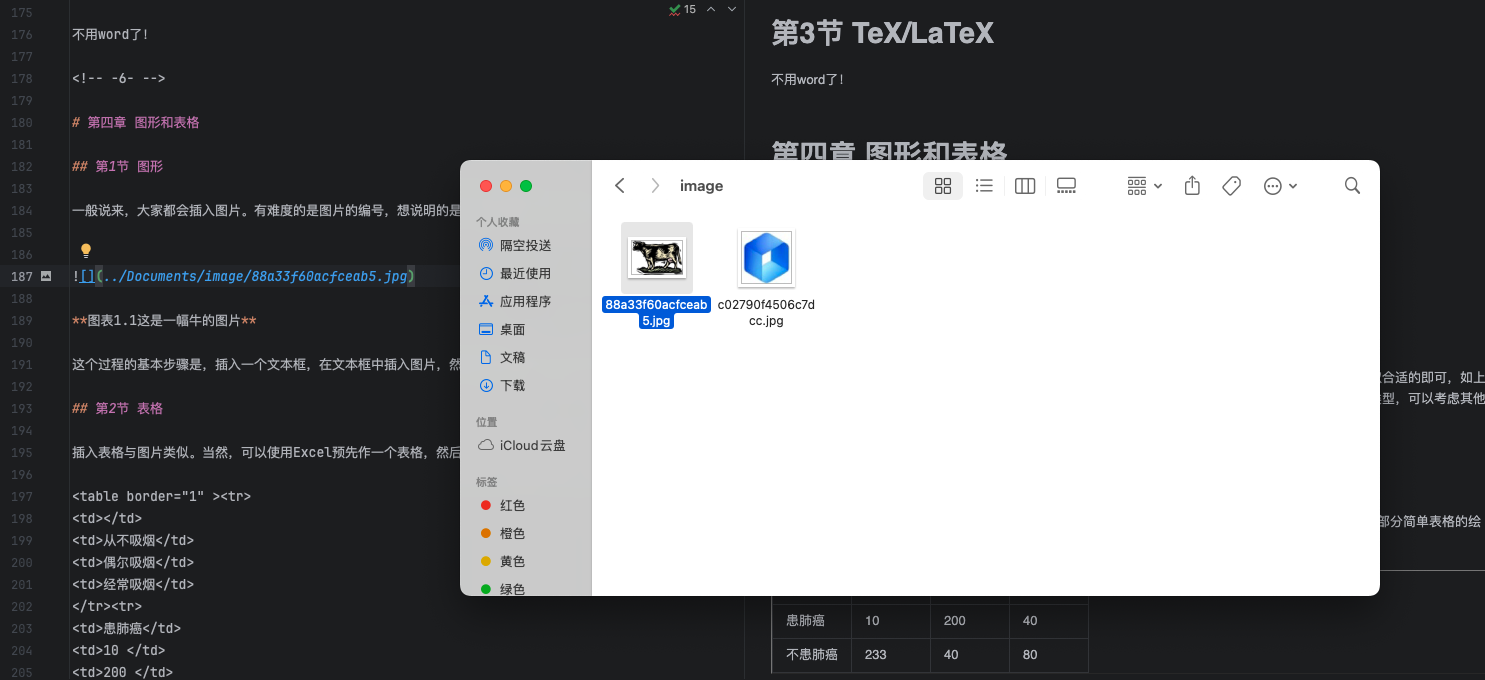
- 如下图:可以看到图片已经保存到本地指定目录下,打开markdown文件可以看到图片链接已经替换为本地图片链接。