TextIn xParse 助力从文档到可操作的数据资产
提供全链路的文档结构化工具,最大化挖掘数据资产价值,您只需关心业务,剩下的交给TextIn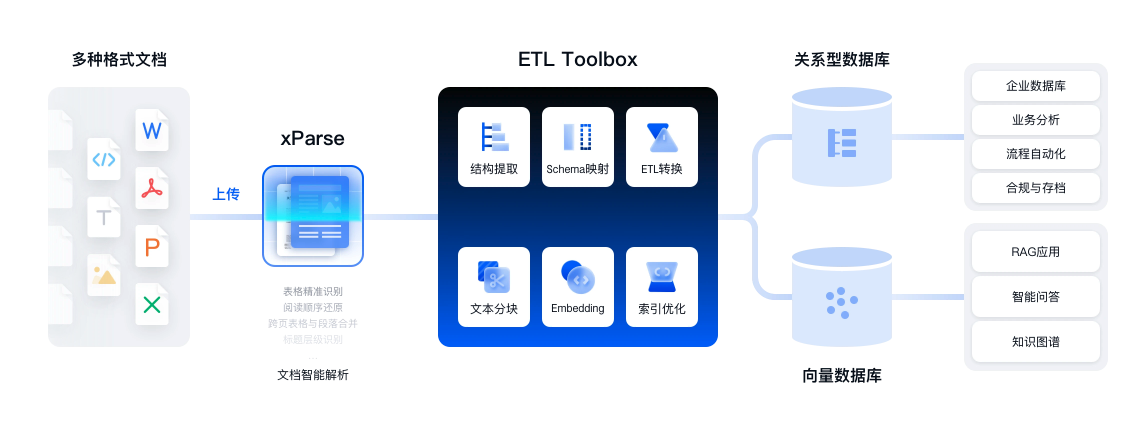
立即试用
在线 Web 平台
免费试用,一站式极速体验解析抽取效果
API
灵活使用不同编程语言,支持接口高度自定义
CLI & SDK
提供可直接复制运行的命令行工具与 SDK,快速将 xParse 文档解析能力集成到开发环境中
第三方 Agent/RAG 平台
适配 Langchain, Dify, RAGFlow 等框架
核心优势
- 支持任意复杂布局:将任意版式的文档拆解为语义完整的段落,并按阅读顺序还原,更加适配大模型。
- 多元素高精度解析:准确提取标题、公式、图表、手写体、印章、跨页段落、页眉页脚、表单字段等各种元素,同时具备行业领先的表格识别能力,轻松解决合并单元格、跨页表格、无线表格等识别难题。
- 强大的语义理解和上下文感知:捕捉更多版面元素间的语义关系,让大模型更加读懂一份文档。
- 强大的预处理工具:无缝集成TextIn平台中的图像处理能力,文档带水印、图片有弯曲、模糊,都能搞定。
- 高精度坐标还原:JSON结果包含高精度的页面、元素、字符级坐标数据,方便人工复核。
- 极简、智能、灵活的语义抽取:xParse提供prompt模式和Schema模式两种抽取规则定制,帮助您根据业务需要实现更灵活的文档信息精准提取。
- 开发者友好:提供清晰的API文档和灵活的集成方式,支持FastGPT、Coze、CherryStudio等主流平台。